selenium 是一个可以模拟浏览器操作的工具,据我所知,不仅仅是 Python,还有其他的编程语言也有支持的 selenium 库,可以作为爬虫或者自动化测试。当然,还有今天要说的,可以使用 selenium 来作为全网页截图工具。
不过,我在使用 selenium 作为全网页截图的过程中,发现了 PhantomJS 的一个“bug”,具体的情况后面详细讲解。
工具简介
使用方式
1、 首先在工具脚本所在的目录下创建一个 urls.txt 文件,用来放置需要批量截图的 URL。格式如同这样:
20,http://jandan.net/ooxx/page-20
21,http://jandan.net/ooxx/page-21
22,http://jandan.net/ooxx/page-22
23,http://jandan.net/ooxx/page-23
即图片需要保存的名称加英文逗号加网页链接。
2、启动工具脚本,会使用多进程批量进行网页截图,截图后的图片保存在当前目录下 pics 文件夹下面,如果这个文件夹不存在则会自动创建。
源码展示
代码是我去年写的,放到了 Github
# -*- coding: utf-8 -*-
from selenium import webdriver
import time
import os.path
import multiprocessing as mp
def readtxt():
'''读取txt文件,返回一个列表,每个元素都是一个元组;文件的格式是图片保存的名称加英文逗号加网页地址'''
with open('urls.txt','r') as f:
lines = f.readlines()
urls = []
for line in lines:
try:
thelist = line.strip().split(",")
if len(thelist) == 2 and thelist[0] and thelist[1]:
urls.append((thelist[0],thelist[1]))
except:
pass
return urls
def get_dir():
'''判断文件夹是否存在,如果不存在就创建一个'''
filename = "pics"
if not os.path.isdir(filename):
os.makedirs(filename)
return filename
def webshot(tup):
driver = webdriver.PhantomJS()
driver.maximize_window()
# 返回网页的高度的js代码
js_height = "return document.body.clientHeight"
picname = str(tup[0])
link = tup[1]
try:
driver.get(link)
k = 1
height = driver.execute_script(js_height)
while True:
if k*500 < height:
js_move = "window.scrollTo(0,{})".format(k * 500)
driver.execute_script(js_move)
time.sleep(0.2)
height = driver.execute_script(js_height)
k += 1
else:
break
driver.save_screenshot('pics'+"\\"+picname+'.png')
print("Process {} get one pic !!!".format(os.getpid()))
time.sleep(0.1)
except Exception as e:
print(picname,e)
if __name__ == '__main__':
t = time.time()
get_dir()
urls = readtxt()
pool = mp.Pool()
pool.map_async(func=webshot,iterable=urls)
pool.close()
pool.join()
print("操作结束,耗时:{:.2f}秒".format(float(time.time()-t)))
源码解读
readtxt() 函数
这个函数的作用是读取自己创建的 urls.txt 文件中的 URL 和截图需要保存的名称,最后返回一个元组,格式就是(picname,url)。
get_dir() 函数
这个函数只有一个作用,就是判断保存图片的文件夹是否存在,如果不存在就创建一个,所以如果是在 Linux 上面操作,就要有权限。
webshot(tup) 函数
这个函数就是这个工具最主要的函数,所做的事情是先读取文件,然后使用 selenium 去启动无头浏览器 PhantomJS 来进行整个网页的截图。
driver = webdriver.PhantomJS()
driver.maximize_window()
上面这两句就是使用 PhantomJS 浏览器来打开浏览器,并且把窗口最大化,之所以使用 PhantomJS 浏览器是因为据我了解,其他的浏览器比如谷歌和火狐都只能但屏幕截图,无法做到整个网页的截图。
js_height = "return document.body.clientHeight"
这一句很重要,代码的注释也写明了,这是一句 JavaScript 语句,作用是返回当前页面的最大可视高度。
但是,很多网页都是一边滑动滚轴一边加载页面的,所以这个 JavaScript 返回的只是当前的页面可视高度,并不一定是整个网页的最终高度,所以如果想要得到一个网页的实际高度,需要重复下滑网页,让网页充分加载才行。
我之前在网上找了很多关于如何把网页加载到底端的方法,找到的基本都是使用 JavaScript 来做的,但是我发现遇到很长的网页根本就行不通,所以我根据自己的理解写了一个 Python 式的,JavaScript 语句主要使用了一个读取当前网页的高度和一个下滑网页的语句。
这个方法就是使用 while 递归,具体的思路是首先使用执行 js 代码获取当前网页可视高度,然后读取每次下滑 500px,让这个下滑的数值跟可视高度对比,如果下滑的总高度小于可视的高度就继续下滑,当然,每次下滑之后都要设置一个延时,这是为了让网页加载出来。直到下滑的总高度大于网页可视高度为止。具体的代码就是下面这个片段:
while True:
if k*500 < height:
js_move = "window.scrollTo(0,{})".format(k * 500)
driver.execute_script(js_move)
time.sleep(0.2)
height = driver.execute_script(js_height)
k += 1
else:
break
浏览器截图的方法如下:
driver.save_screenshot('pics'+"\\"+picname+'.png')
这个方法默认的第一个参数就是图片保存的文件名称
其实整个的截图过程并不难,只要理解了将网页滑到底端的方法就行。
多进程截图
这个就比较简单了,直接使用 Python 的基础库 multiprocessing 就行了,然后设置一个进程池来批量截图。
因为我的电脑是4核的,所以自动开启了4个进程来操作,我设置了41个煎蛋网的妹子图的链接用来测试截图的效果,最终花了463秒,这个多进程的效果还是非常明显的(速度是单进程的4倍)。测试的输出结果部分显示如下:
...
Process 9784 get one pic !!!
Process 7692 get one pic !!!
Process 11056 get one pic !!!
Process 8296 get one pic !!!
Process 9784 get one pic !!!
Process 9784 get one pic !!!
Process 11056 get one pic !!!
操作结束,耗时:463.42秒
最后截到的图片结果如图所示:
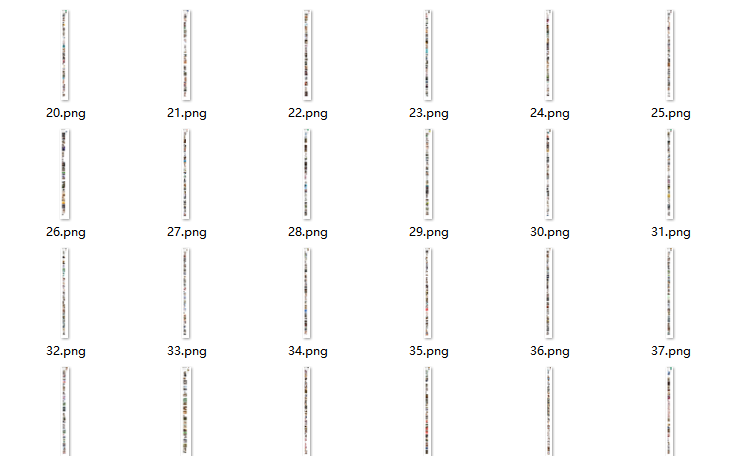
一个 Bug
到目前为止,上面的整个过程并没有任何问题,我发现的这个 bug 并不是我的代码有问题,而是 PhantomJS 的截图的最大显示图片长度有问题。
我测试了一个网页非常长的链接(总长度超过36000px),然后我发现最后截取到的网页的图片根本没有到达网页的底部,具体的效果图如下:

这个图片长度有36277px,但是实际上显示出来图片的高度只有32767px,看看在 PS 里面的效果:
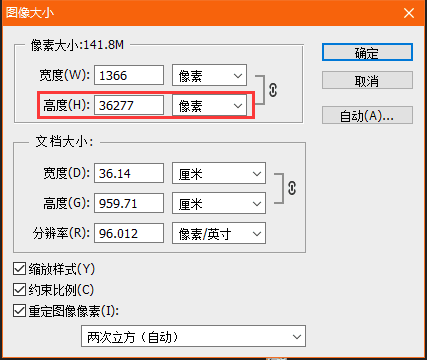
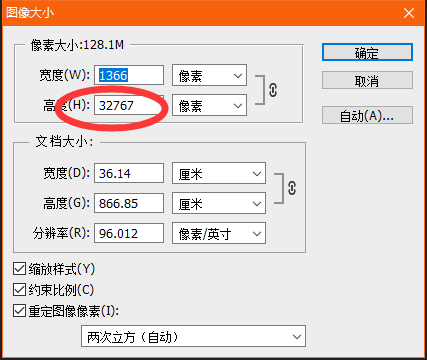
一开始我以为这个只是这个网页的加载问题,可能是后面的一段没有加载出来,所以截图的时候没有截到后面的一段。但是后来我试了几个其他的比较长的网页,发现只要网页超过了32767px,就只能截取到32757px的页面信息,其他的部分显示为透明。
经过百度32767这个数字,发现原来这是int(32位)也就是整形的最大值,虽然不知道到底代表什么,但是这个特殊的值足以说明 PhantomJS 截图的这个问题应该不是一个 BUG,而是某种特殊的原因所致。
后记:这个工具的代码和测试都是我去年写的,当时由于查找关于如何把网页滑到底部的方式查了好久,后来还是自己按照自己的理解写出来了一个很 Python 式的,所以就记录了下来。而且,一直也没有查到关于发哦发现的这个 bug 的解决方式和具体的原因,也算是记录一下,后面如果能够知道其中的原因再来改。
版权声明:如无特殊说明,文章均为本站原创,转载请注明出处
本文链接:https://tendcode.com/subject/article/PhantomJS-screenshot/
许可协议:署名-非商业性使用 4.0 国际许可协议









MulongXie
6 楼 - 6 年,1月前
chrome 也可以, 方法如下