之前在鱼C论坛的时候,看到很多人都在用 Python 写爬虫爬煎蛋网的妹子图,当时我也写过,爬了很多的妹子图片。后来煎蛋网把妹子图的网页改进了,对图片的地址进行了加密,所以论坛里面的人经常有人问怎么请求的页面没有链接。这篇文章就来说一下煎蛋网 OOXX 妹子图的链接获取方式。
首先说明一下,之前煎蛋网之所以增加了反爬虫机制,应该就是因为有太多的人去爬他们的网站了。爬虫频繁的访问网站会给网站带来压力,所以,建议大家写爬虫简单的运行成功就适可而止,不要过分地去爬别人的东西。
爬虫思路分析
图片下载流程图
首先,用一张简单的流程图(非规范流程图格式)来展示一下爬取简单网的妹子图的整个流程:
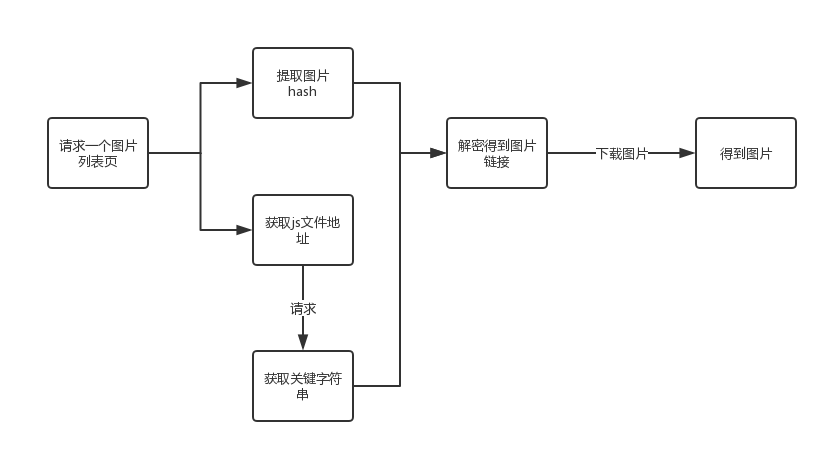
流程图解读
1、爬取煎蛋网的妹子图,我们首先要打开任意一个妹子图的页面,比如 http://jandan.net/ooxx/page-44#comments 然后,我们需要请求这个页面,获取2个关键的信息(后续会说明信息的具体作用),其中第一个信息是每个妹子图片的 hash 值,这个是后续用来解密生成图片地址的关键信息。
2、在页面中除了提取到图片的 hash 之外,还有提取到当前页的一个关键的 js 文件的地址,这个 js 文件中包含了一个同样是用来生成图片地址的关键参数,要得到这个参数,必须去请求这个 JS 地址,当时妹子图的每个页面的 js 地址是不同的,所以需要从页面中提取。
3、得到了图片的 hash 和 js 中的关键参数之后,可以根据 js 中提供的解密方式,得到图片的链接,这个解密方式后续用 Python 代码和 js 代码的参照来说明。
4、有了图片链接,下载图片就不多说了,后续会有第二篇文章,来使用多线程+多进程的方式下载图片。
页面分析
网页源代码解读
我们可以打开一个妹子图的页面,还是最开始的 http://jandan.net/ooxx/page-44#comments 为例,然后查看源代码(注意,不是审查元素),可以看到本应该放图片地址的地方并没有图片地址,而是类似于下面的代码:
<p><img src="//img.jandan.net/img/blank.gif" onload="jandan_load_img(this)" /><span class="img-hash">ece8ozWUT/VGGxW1hlbITPgE0XMZ9Y/yWpCi5Rz5F/h2uSWgxwV6IQl6DAeuFiT9mH2ep3CETLlpwyD+kU0YHpsHPLnY6LMHyIQo6sTu9/UdY5k+Vjt3EQ</span></p>
从这个代码可以看出来,图片地址被一个 js 函数代替了,也就是说图片地址是由这个jandan_load_img(this)函数来获取并加载的,所以,现在的关键是,需要到 JS 文件中查找这个函数的意义。
js 文件解读
通过在每个 js 文件中搜索jandan_load_img,最后可以在一个地址类似于 http://cdn.jandan.net/static/min/1d694f08895d377af4835a24f06090d0.29100001.js 的文件中找到这个函数的定义,将压缩的 JS 代码格式化查看,可以看到具体的定义如下片段:
function jandan_load_img(b) {
var d = $(b);
var f = d.next("span.img-hash");
var e = f.text();
f.remove();
var c = f_Qa8je29JONvWCrmeT1AJocgAtaiNWkcN(e, "agC37Is2vpAYzkFI9WVObFDN5bcFn1Px");
这段代码的意思很容易看懂,首先它提取了当前标签下 css 为img-hash的 span 标签的文本,也就是我们最开始说的图片的 hash 值,然后把这个值和一个字符串参数(每个页面的这个参数是变动的,这个页面是 agC37Is2vpAYzkFI9WVObFDN5bcFn1Px)一起传递到另外一个函数f_Qa8je29JONvWCrmeT1AJocgAtaiNWkcN中,所以我们还要去查看这个函数的意义才行,这个函数就是用来生成图片链接的函数了。
f_ 函数的解读
可以在 js 中查找这个 f_ 函数的定义,可以看到有两个,但是没关系,根据代码从上到下执行的规律,我们只需要看比较靠后的那个就行了,完整的内容如下:
var f_Qa8je29JONvWCrmeT1AJocgAtaiNWkcN = function(m, r, d) {
var e = "DECODE";
var r = r ? r : "";
var d = d ? d : 0;
var q = 4;
r = md5(r);
var o = md5(r.substr(0, 16));
var n = md5(r.substr(16, 16));
if (q) { if (e == "DECODE") { var l = m.substr(0, q) } } else { var l = "" }
var c = o + md5(o + l);
var k;
if (e == "DECODE") {
m = m.substr(q);
k = base64_decode(m)
}
var h = new Array(256);
for (var g = 0; g < 256; g++) { h[g] = g }
var b = new Array();
for (var g = 0; g < 256; g++) { b[g] = c.charCodeAt(g % c.length) }
for (var f = g = 0; g < 256; g++) {
f = (f + h[g] + b[g]) % 256;
tmp = h[g];
h[g] = h[f];
h[f] = tmp
}
var t = "";
k = k.split("");
for (var p = f = g = 0; g < k.length; g++) {
p = (p + 1) % 256;
f = (f + h[p]) % 256;
tmp = h[p];
h[p] = h[f];
h[f] = tmp;
t += chr(ord(k[g]) ^ (h[(h[p] + h[f]) % 256]))
}
if (e == "DECODE") { if ((t.substr(0, 10) == 0 || t.substr(0, 10) - time() > 0) && t.substr(10, 16) == md5(t.substr(26) + n).substr(0, 16)) { t = t.substr(26) } else { t = "" } }
return t
};
这个函数需要传递3个参数,第一个参数是图片的 hash 值,第二个参数就是在jandan_load_img函数中看到的一个字符串,第三个参数其实没用,因为在jandan_load_img函数中根本没有传入。我们只需要按照 JS 代码的意思把这个函数改写成 Python 代码就行了。
Python改写函数
使用Python将f_函数改写之后应该是这样的:
def get_imgurl(m, r='', d=0):
'''解密获取图片链接'''
e = "DECODE"
q = 4
r = _md5(r)
o = _md5(r[0:0 + 16])
n = _md5(r[16:16 + 16])
l = m[0:q]
c = o + _md5(o + l)
m = m[q:]
k = _base64_decode(m)
h = list(range(256))
b = [ord(c[g % len(c)]) for g in range(256)]
f = 0
for g in range(0, 256):
f = (f + h[g] + b[g]) % 256
tmp = h[g]
h[g] = h[f]
h[f] = tmp
t = ""
p, f = 0, 0
for g in range(0, len(k)):
p = (p + 1) % 256
f = (f + h[p]) % 256
tmp = h[p]
h[p] = h[f]
h[f] = tmp
t += chr(k[g] ^ (h[(h[p] + h[f]) % 256]))
t = t[26:]
return t
这个函数需要用到另外两个函数,第一个是 MD5 加密的函数,这个函数对应的是 JS 中这样的段落:
var o = md5(r.substr(0, 16));
js 的substr()函数其实就是 Python 里面的切片的用法,稍微查看一下定义就能懂,不解释。
MD5 加密转化成 Python 版本如下:
def _md5(value):
'''md5加密'''
m = hashlib.md5()
m.update(value.encode('utf-8'))
return m.hexdigest()
然后还有一个 bash64 的解码函数,这个函数在 js 中的这一个段用到了:
k = base64_decode(m)
使用 Python 的时候需要注意,如果直接使用 Python 的base64.b64decode的话会报错,具体的报错内容是:
binascii.Error: Incorrect padding
所以在将数据进行解码之前先要处理一下,具体的函数是:
def _base64_decode(data):
'''bash64解码,要注意原字符串长度报错问题'''
missing_padding = 4 - len(data) % 4
if missing_padding:
data += '=' * missing_padding
return base64.b64decode(data)
到这里,获取图片链接的函数就完成了,主要就是使用3个函数。
我们可以传入两个从网页中复制到的参数到这个函数中测试一下:
m = 'ece8ozWUT/VGGxW1hlbITPgE0XMZ9Y/yWpCi5Rz5F/h2uSWgxwV6IQl6DAeuFiT9mH2ep3CETLlpwyD+kU0YHpsHPLnY6LMHyIQo6sTu9/UdY5k+Vjt3EQ'
r = 'HpRB2OSft5RhlSyZaXV8xYpvEAgDThcA'
print(get_imgurl(m,r))
可以看到如下输出:
//ww3.sinaimg.cn/mw600/0073ob6Pgy1fpet9wku7dj30hs0qljuz.jpg
注意:这里的r参数是从每个页面中的 js 中复制的,每个页面的 js 地址是变动的,这个参数也是变动的。
获取 hash 和 js 地址
之前说过,hash 值是获取图片地址的关键参数,而另外的参数在 js 文件中,并且这个 js 文件每个页面不同,所以现在来提取这两个关键参数。
批量获取 hash
获取图片的 hash 值很方便,我们可以使用 BeautifulSoup 的方法即可,具体的代码片段:
def get_urls(url):
'''获取一个页面的所有图片的链接'''
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:47.0) Gecko/20100101 Firefox/47.0',
'Host': 'jandan.net'
}
html = requests.get(url, headers=headers).text
js_url = 'http:' + re.findall('<script src="(//cdn.jandan.net/static/min/[\w\d]+\.\d+\.js)"></script>', html)[-1]
_r = get_r(js_url)
soup = BeautifulSoup(html, 'lxml')
tags = soup.select('.img-hash')
for tag in tags:
img_hash = tag.text
img_url = get_imgurl(img_hash,_r)
print(img_url)
提取图片 hash 的代码是这一句:
soup = BeautifulSoup(html, 'lxml')
tags = soup.select('.img-hash')
for tag in tags:
img_hash = tag.text
获取 js 中关键字符串
而获取 js 地址的方式是使用的正则表达式:
js_url = 'http:' + re.findall('<script src="(//cdn.jandan.net/static/min/[\w\d]+\.\d+\.js)"></script>', html)[-1]
这里要注意,因为正则提取的是一个列表,所以最后需要取列表中的一个链接,经过查看,我发现有的页面有两个这种 JS 文件,有一个是被注释掉了,所以都要使用最后一个,这个的表达方式是列表索引中使用[-1]取最后一个。
得到 js 地址之后需要请求,然后找到关键字符串,具体可以写成一个函数:
def get_r(js_url):
'''获取关键字符串'''
js = requests.get(js_url).text
# 之前是使用下面注释的这个,后来煎蛋改了这个函数的名称
# _r = re.findall('c=f_[\w\d]+\(e,"(.*?)"\)', js)[0]
_r = re.findall('c=[\w\d]+\(e,"(.*?)"\)', js)[0]
return _r
完整代码
下面就是获取一个页面的全部的图片链接的完整代码:
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
import hashlib
import re
import base64
def _md5(value):
'''md5加密'''
m = hashlib.md5()
m.update(value.encode('utf-8'))
return m.hexdigest()
def _base64_decode(data):
'''bash64解码,要注意原字符串长度报错问题'''
missing_padding = 4 - len(data) % 4
if missing_padding:
data += '=' * missing_padding
return base64.b64decode(data)
def get_imgurl(m, r='', d=0):
'''解密获取图片链接'''
e = "DECODE"
q = 4
r = _md5(r)
o = _md5(r[0:0 + 16])
n = _md5(r[16:16 + 16])
l = m[0:q]
c = o + _md5(o + l)
m = m[q:]
k = _base64_decode(m)
h = list(range(256))
b = [ord(c[g % len(c)]) for g in range(256)]
f = 0
for g in range(0, 256):
f = (f + h[g] + b[g]) % 256
tmp = h[g]
h[g] = h[f]
h[f] = tmp
t = ""
p, f = 0, 0
for g in range(0, len(k)):
p = (p + 1) % 256
f = (f + h[p]) % 256
tmp = h[p]
h[p] = h[f]
h[f] = tmp
t += chr(k[g] ^ (h[(h[p] + h[f]) % 256]))
t = t[26:]
return t
def get_r(js_url):
'''获取关键字符串'''
js = requests.get(js_url).text
_r = re.findall('c=[\w\d]+\(e,"(.*?)"\)', js)[0]
return _r
def get_urls(url):
'''获取一个页面的所有图片的链接'''
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:47.0) Gecko/20100101 Firefox/47.0',
'Host': 'jandan.net'
}
html = requests.get(url, headers=headers).text
js_url = 'http:' + re.findall('<script src="(//cdn.jandan.net/static/min/[\w\d]+\.\d+\.js)"></script>', html)[-1]
_r = get_r(js_url)
soup = BeautifulSoup(html, 'lxml')
tags = soup.select('.img-hash')
for tag in tags:
img_hash = tag.text
img_url = get_imgurl(img_hash,_r)
print(img_url)
if __name__ == '__main__':
get_urls('http://jandan.net/ooxx/page-44')
运行上面的代码,可以打印出这个页面的所有图片链接,部分链接如下:
//ww3.sinaimg.cn/mw600/0073ob6Pgy1fpet9wku7dj30hs0qljuz.jpg
//ww3.sinaimg.cn/mw600/0073tLPGgy1fpet9mszjwj30hs0g1jsv.jpg
//ww3.sinaimg.cn/mw600/0073ob6Pgy1fpesskkgobj31jk1jkk5b.jpg
//wx3.sinaimg.cn/mw600/006XfbArly1fpesq2jn1vj30j60svaz3.jpg
//wx3.sinaimg.cn/mw600/6967abd2gy1fpenoyobrcj20u03d0b2d.jpg
//wx3.sinaimg.cn/mw600/6967abd2gy1fpenp38v9uj20u03zkhdy.jpg
总结:到这里为止,提取煎蛋网妹子图的图片链接的方式其实已经给出来了,下一篇会接着讲通过多线程+多进程的方式下载图片。
版权声明:如无特殊说明,文章均为本站原创,转载请注明出处
本文链接:https://tendcode.com/subject/article/jiandan-meizi-spider/
许可协议:署名-非商业性使用 4.0 国际许可协议









mrdun
13 楼 - 5 年前