上一篇文章全面解析了煎蛋网的妹子图的图片链接解密的方式,已经可以通过 Python 爬虫代码批量获取每个页面中的图片地址。但是上一篇文章中并没有写图片下载的函数,这一篇文章就来使用 Python 的多线程和多进程来批量下载图片。
首先,没有看上一篇图片地址获取方式的请先查看上一篇文章 [Python爬虫]煎蛋网OOXX妹子图爬虫(1)——解密图片地址
多线程下载
多线程源代码
def load_imgs(url,file):
'''多线程下载单页的所有图片'''
threads = []
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.8; rv:49.0) Gecko/20100101 Firefox/49.0',
'Host': 'jandan.net'
}
html = requests.get(url, headers=headers).text
soup = BeautifulSoup(html, 'lxml')
# 这个地方必须使用[-1]来提取js地址,因为有的页面有两个js地址,其中第一个是被注释了不用的
js_url = re.findall('<script src="(//cdn.jandan.net/static/min/[\w\d]+\.\d+\.js)"></script>', html)[-1]
_r = get_r('http:{}'.format(js_url))
tags = soup.select('.img-hash')
for each in tags:
hash = each.text
img_url = 'http:' + get_imgurl(hash, _r)
t = threading.Thread(target=load_img,args=(img_url,file))
threads.append(t)
for i in threads:
i.start()
for i in threads:
i.join()
print(url,'is ok')
多线程代码解读
- 这是一个爬虫类(上一篇中提到的,本文末尾也会给出完整代码)的函数,这个函数需要传递2个参数,第一个参数是一个地址,也就是需要下载图片的网页,第二个参数是一个本地文件夹的地址,也就是图片下载之后保存的文件夹。
- 思路很简单,就是先请求当前页,然后先调用第一篇文章中的函数去获取图片的 hash 值和 js 中的关键字符串参数,然后再调用图片链接解密函数,得到图片的真实地址,最后调用一个图片下载函数 load_img 使用多线程下载图片。
- 下载图片的函数如下:
def load_img(imgurl, file):
'''下载单张图片到制定的文件夹下'''
name = imgurl.split('/')[-1]
file = "{}\\{}".format(file,name)
item = requests.get(imgurl).content
with open(file,'wb') as f:
f.write(item)
print('{} is loaded'.format(name))
这个函数就很简单了,就是传入一个图片的地址和需要保存图片的文件地址,然后写入图片就行了,不多说。
- 多线程的实现:
这里是使用的 Python 内置的多线程方式,首先创建一个放线程的列表:
threads = []
然后将当前页面中的每个图片链接最为参数传入到线程中,而线程中的第一个函数参数就是上面提到的下载图片的函数了,具体代码是这一段:
t = threading.Thread(target=load_img,args=(img_url,file))
threads.append(t)
最后运行多线程即可:
for i in threads:
i.start()
for i in threads:
i.join()
以上代码就是实现的单个页面的多线程下载图片的方式,因为下载图片是一个IO密集型的操作,所以使用多线程可以有效的提高图片下载的效率,更重要的是图片下载是互相不影响的,所以也不需要去设置线程锁,这算是很简单的多线程操作了。
多进程下载
上面的的多线程下载实现了单个页面的图片使用多线程去下载,如果我们要实现同时去请求多个页面呢?当然,一样可以使用多线程,首先多线程请求多个页面,然后多线程下载多个图片,也就是多线程中嵌套多线程的做法。不过为了展示 Python 多进程的用法,这里实现的是使用多进程中嵌套多线程的方法。
多进程代码展示
def main(start,end,file):
'''多进程下载多页的图片,传入参数是开始页码数,结束页码,图片保存文件夹地址'''
pool = multiprocessing.Pool(processes=4)
base_url = 'http://jandan.net/ooxx/page-{}'
for i in range(start,end+1):
url = base_url.format(i)
pool.apply_async(func=load_imgs,args=(url,file))
pool.close()
pool.join()
多进程代码解读
- 上面这个函数是整个爬虫类最终要运行的函数,它需要3个参数,前面两个参数是需要爬取的页面的起始页码和终止页码,第3个参数同样是图片保存的文件夹地址。
- 首先创建一个进程池:
pool = multiprocessing.Pool(processes=4)
当然,整个进程池我设置了4个进行,这个进程数的数量可以自己去设定。
- 循环创建下载链接,然后加入到进程池中:
for i in range(start,end+1):
url = base_url.format(i)
pool.apply_async(func=load_imgs,args=(url,file))
这个操作其实跟多线程的使用非常相识,同样是给进程池的函数传递2个参数,第一个参数就是之前用来多线程下载单页图片的下载函数,第二个参数就是需要传递给下载函数的参数,也就是链接和文件夹地址。
- 运行多进行:
pool.close()
pool.join()
多进程添加完毕就可以运行起来了,最后可以查看运行的效果,打印一下消耗的时间,可以去跟单进程单线程对比,应该会快很多。
if __name__ == '__main__':
import time
t = time.time()
main(23,25,r'C:\Users\Hopetree\Desktop\meizi')
print(time.time()-t)
- 运行部分效果如下:
46401622gy1fp9obr1iwzj20hs0hs408.jpg is loaded
0073ob6Pgy1fpa9qda270g304s06m4qp.gif is loaded
0073ob6Pgy1fpam2nkjrmg308r08me84.gif is loaded
http://jandan.net/ooxx/page-25 is ok
0073ob6Pgy1fp9ptkxfirg308w06oe83.gif is loaded
http://jandan.net/ooxx/page-23 is ok
006GJYM5gy1fp9vomnhvvg30dc0goqv9.gif is loaded
46401622gy1fpab28pdkcg20g70k8he1.gif is loaded
46401622gy1fpabhbyq2vg20g70k84qx.gif is loaded
http://jandan.net/ooxx/page-24 is ok
74.57059788703918
最后去自己输入的图片保存的文件夹中就能看到下载好的图片了
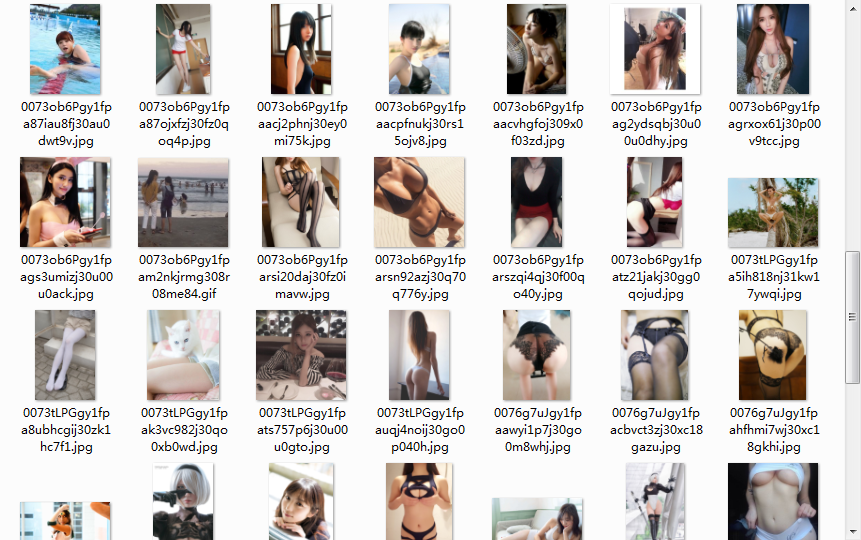
完整代码
从第一篇到第二篇的完整代码如下,只需要修改最后运行的函数中页码的起始页码数和自己想要保存的文件夹地址,就可以运行爬虫程序了。
# -*- coding: utf-8 -*-
import hashlib
import base64
import requests
from bs4 import BeautifulSoup
import re
import threading
import multiprocessing
def _md5(value):
'''md5加密'''
m = hashlib.md5()
m.update(value.encode('utf-8'))
return m.hexdigest()
def _base64_decode(data):
'''bash64解码,要注意原字符串长度报错问题'''
missing_padding = 4 - len(data) % 4
if missing_padding:
data += '=' * missing_padding
return base64.b64decode(data)
def get_imgurl(m, r='', d=0):
'''解密获取图片链接'''
e = "DECODE"
q = 4
r = _md5(r)
o = _md5(r[0:0 + 16])
n = _md5(r[16:16 + 16])
l = m[0:q]
c = o + _md5(o + l)
m = m[q:]
k = _base64_decode(m)
h = list(range(256))
b = [ord(c[g % len(c)]) for g in range(256)]
f = 0
for g in range(0, 256):
f = (f + h[g] + b[g]) % 256
tmp = h[g]
h[g] = h[f]
h[f] = tmp
t = ""
p, f = 0, 0
for g in range(0, len(k)):
p = (p + 1) % 256
f = (f + h[p]) % 256
tmp = h[p]
h[p] = h[f]
h[f] = tmp
t += chr(k[g] ^ (h[(h[p] + h[f]) % 256]))
t = t[26:]
return t
def get_r(js_url):
'''获取关键字符串'''
js = requests.get(js_url).text
# 之前用的下面注释掉的这个,后来煎蛋改了函数名称,少个f_
# _r = re.findall('c=f_[\w\d]+\(e,"(.*?)"\)', js)[0]
_r = re.findall('c=[\w\d]+\(e,"(.*?)"\)', js)[0]
return _r
def load_img(imgurl, file):
'''下载单张图片到制定的文件夹下'''
name = imgurl.split('/')[-1]
file = "{}\\{}".format(file,name)
item = requests.get(imgurl).content
with open(file,'wb') as f:
f.write(item)
print('{} is loaded'.format(name))
def load_imgs(url,file):
'''多线程下载单页的所有图片'''
threads = []
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.8; rv:49.0) Gecko/20100101 Firefox/49.0',
'Host': 'jandan.net'
}
html = requests.get(url, headers=headers).text
soup = BeautifulSoup(html, 'lxml')
# 这个地方必须使用[-1]来提取js地址,因为有的页面有两个js地址,其中第一个是被注释了不用的
js_url = re.findall('<script src="(//cdn.jandan.net/static/min/[\w\d]+\.\d+\.js)"></script>', html)[-1]
_r = get_r('http:{}'.format(js_url))
tags = soup.select('.img-hash')
for each in tags:
hash = each.text
img_url = 'http:' + get_imgurl(hash, _r)
t = threading.Thread(target=load_img,args=(img_url,file))
threads.append(t)
for i in threads:
i.start()
for i in threads:
i.join()
print(url,'is ok')
def main(start,end,file):
'''多进程下载多页的图片,传入参数是开始页码数,结束页码,图片保存文件夹地址'''
pool = multiprocessing.Pool(processes=4)
base_url = 'http://jandan.net/ooxx/page-{}'
for i in range(start,end+1):
url = base_url.format(i)
pool.apply_async(func=load_imgs,args=(url,file))
pool.close()
pool.join()
if __name__ == '__main__':
import time
t = time.time()
main(23,25,r'C:\Users\Hopetree\Desktop\meizi')
print(time.time()-t)
总结:以上就是使用多进程+多线程下载煎蛋网妹子图的所有代码,我在代码中没有设置延时时间,因为想要测试爬虫的效率,毕竟我也就爬了3页。当然,希望看到这篇文章的人如果要大量爬图片的话,尽量设置足够的 sleep 时间来延时爬取,这样既可以避免自己的 IP 被封,也不至于给煎蛋的服务器带来压力。
版权声明:如无特殊说明,文章均为本站原创,转载请注明出处
本文链接:https://tendcode.com/subject/article/jiandan-meizi-spider-2/
许可协议:署名-非商业性使用 4.0 国际许可协议










jiaqi0223
13 楼 - 1 年前
牛逼牛逼~~~