现在各个音乐平台想要听杰伦的歌或者下载歌曲都需要购买 VIP,而且即使是 VIP 用户,下载歌曲也是有数量限制的。于是随手百度了一下周杰伦的歌曲下载资源,搜到了新浪微盘上面有人分享了一份歌单,大概收集了近200首歌曲,于是本着能自动化就不手动操作的原则,就想着写一个爬虫来批量下载歌曲。
分析了一波新浪微盘的请求接口之后,一时卡在了提取歌曲下载链接的接口请求上,于是无奈选择了直接使用 selenium 来模拟浏览器进行批量下载歌曲。
备注:写完这个 selenium 爬虫之后,我又分析清楚了提取和构造各个接口的方式,可以直接使用接口来下载歌曲,后续会单独写一篇文章分享一下整个的思路,敬请期待吧!
页面分析
微盘上面别人分享的周杰伦歌曲的地址是 https://vdisk.weibo.com/s/tg6IJ27yogat5
列表页分析
首先,打开这个微盘页面可以看到每页大概有20首左右的歌曲,而每首歌都有一个下载页面,所以需要提取到每首歌的下载页面,提取的方式有多种,我比较喜欢用 xpath 语法提取。提取的思路截图如下:
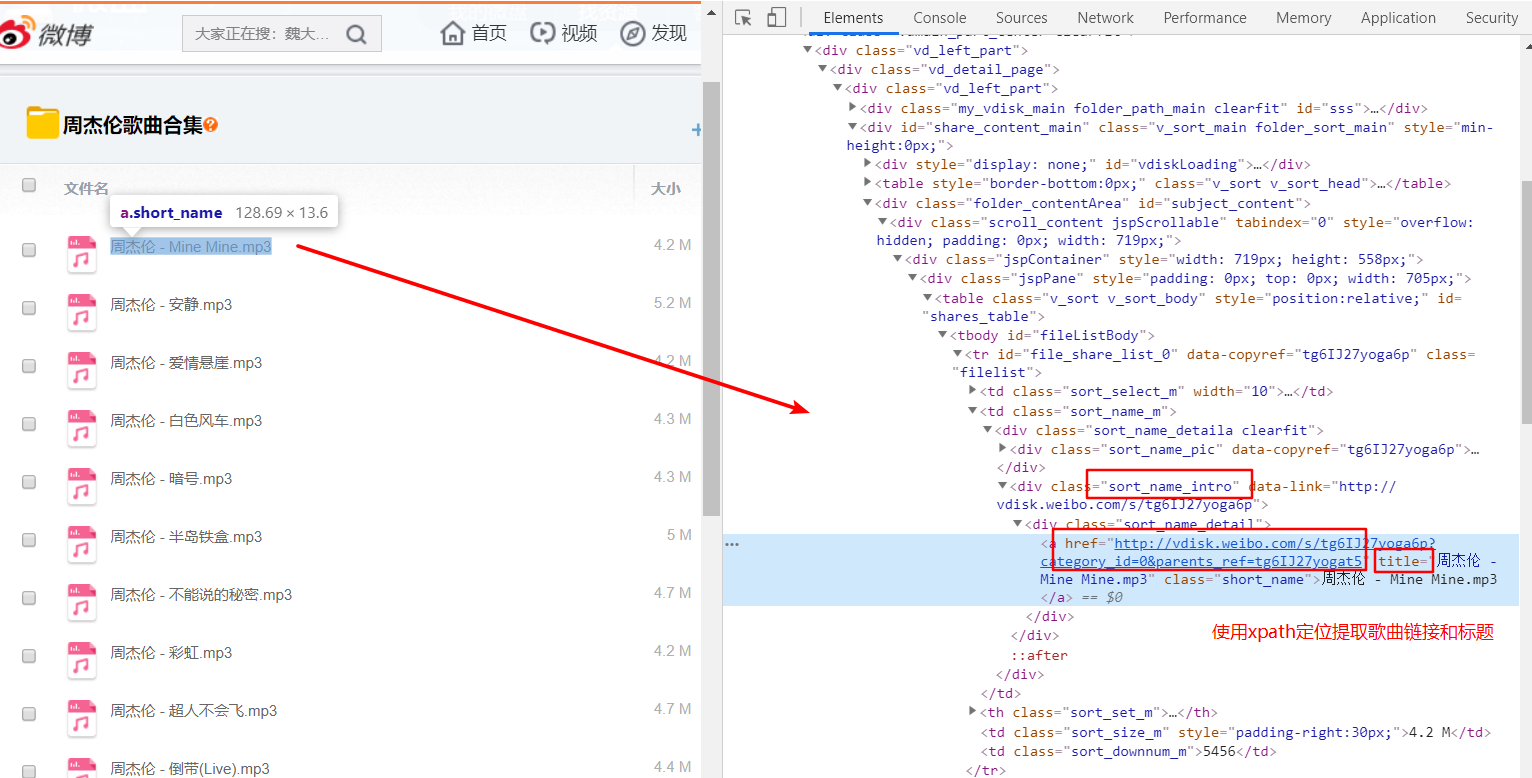
可以看到所有歌曲都在一个 a 标签中,这个标签里面有歌曲链接,还有歌曲的名称,分别是在 href 属性和 title 属性中,xpath 语法如下:
//div[@class="sort_name_intro"]/div/a
下载页分析
提取到每首歌的下载页面地址之后,可以进入下载页,可以看到每个页面都有一个下载的按钮,点击这个按钮之后浏览器就开始下载歌曲了。
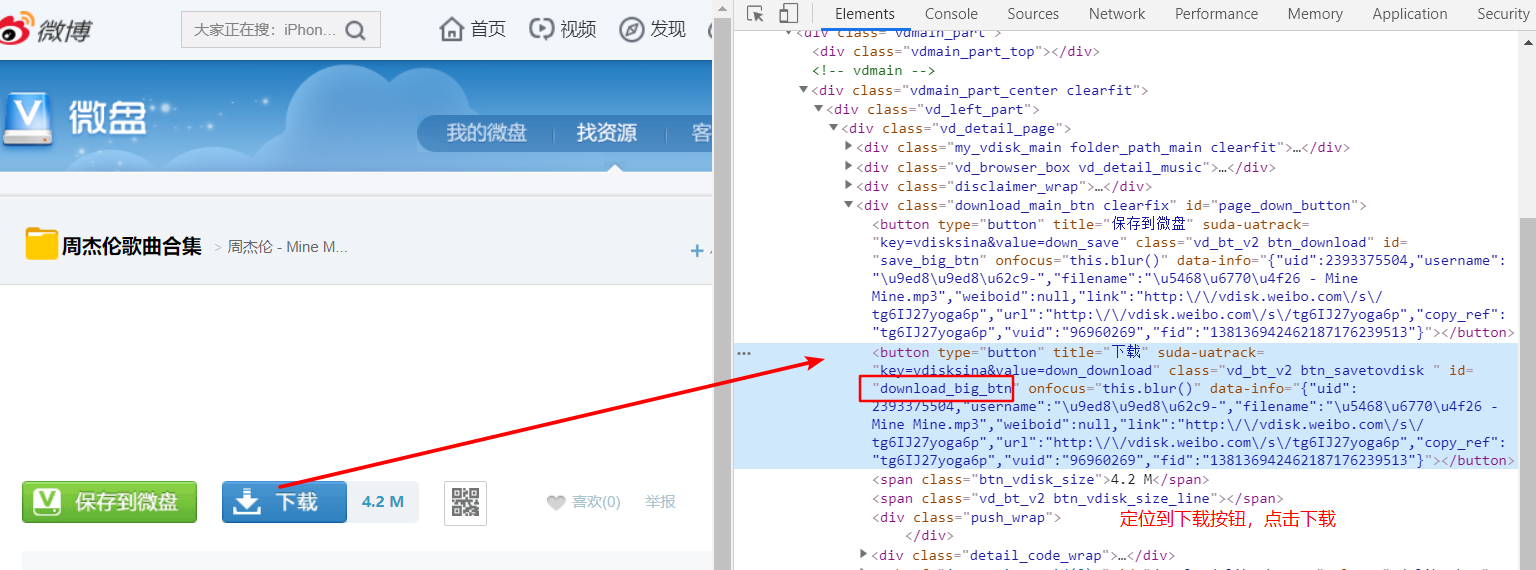
同样可以使用 xpath 语法定位到按钮的位置,然后进行点击即可,xpath 语法如下:
//*[@id="download_big_btn"]
分页
上面两个步骤可以实现一个页面的所有歌曲的下载,但是这个歌单是包括很多个页面的,所以需要实现分页点击的操作。一般来说,分页的操作可以分为两个思路,第一个是使用循环的方式来请求页面,这种方式适合于已知所以页面的地址(或者是可以构建出所有页面地址),其实这里就可以使用这种方式,因为已经可以看出这个分享总共有10页,而且每一页的地址也很好构造出来;不过我这里并不想用这种方式,而是采用第二种更加严谨的方式,那就是使用递归的方式翻页,思路就是在当前页面提取“下一页”的按钮,然后点击到下一页,然后进行递归,直到没有下一页为止。
这里可以看到在首页只有“下一页”按钮,在末页只有“上一页”按钮,中间的页面两个按钮都有,所以这里的思路是定位到有“下一页”的按钮的时候就进行递归,一旦没有定位到,递归就结束了,所以有始有终。
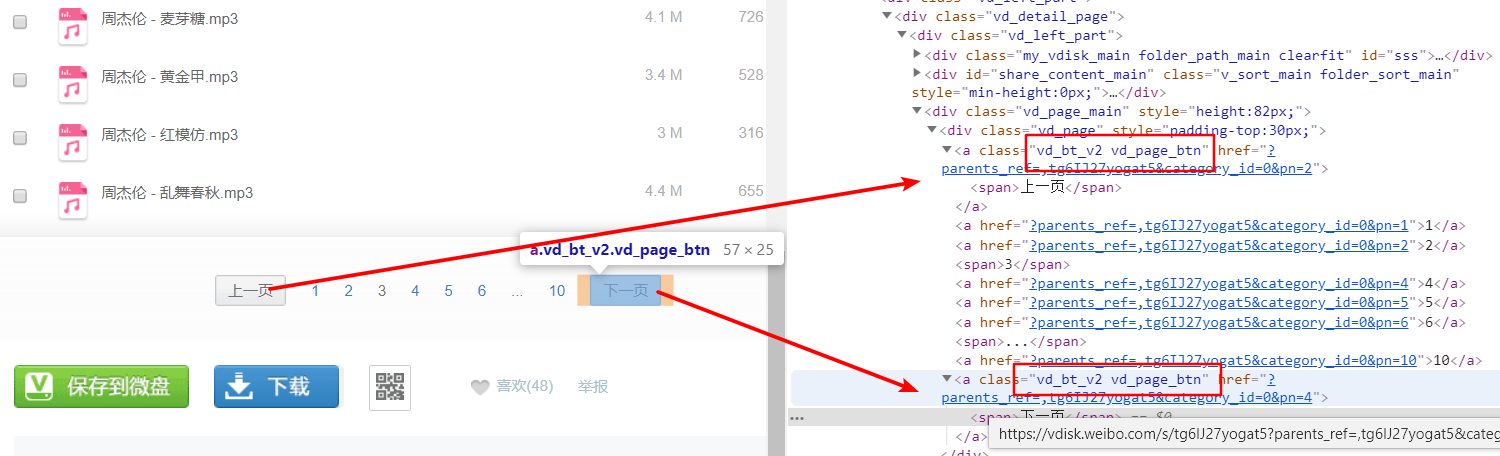
翻页的 xpath 语法是
//div[@class="vd_page"]/a[@class="vd_bt_v2 vd_page_btn"]
不过这个定位到的是“上一页”和“下一页”都能定位到,所以需要通过文字判断是不是“下一页”,这个后续代码分析中会看到具体判断。
爬虫代码解析
通过上面对页面的分析,可以整理一下爬虫的思路,主要步骤如下:
- 提取当前页的所有歌曲的下载页地址及标题
- 定位到下一页,递归翻页提取歌曲下载页地址
- 进入歌曲下载页,点击下载按钮完成下载
源代码分享
源码地址:https://github.com/Hopetree/Spiders100/tree/master/sina-weipan
# -*- coding:utf-8 -*-
'''
爬取新浪的微盘中歌曲(周杰伦的)
然后下载歌曲到本地
'''
import time
from concurrent.futures import ThreadPoolExecutor
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
class Weipan(object):
def __init__(self, url):
self.baseurl = url
self.items = []
self.driver = webdriver.Chrome()
self.driver.maximize_window()
self.waiter = WebDriverWait(self.driver, 5)
def search_info_by_url(self, url):
self.driver.get(url)
item_selectors = self.waiter.until(
EC.presence_of_all_elements_located((By.XPATH, '//div[@class="sort_name_intro"]/div/a'))
)
for item_selector in item_selectors:
item_link = item_selector.get_attribute('href')
item_title = item_selector.get_attribute('title')
self.items.append((item_title, item_link))
# 提取下一页的链接,并递归提取信息
page_selectors = self.waiter.until(
EC.presence_of_all_elements_located((By.XPATH, '//div[@class="vd_page"]/a[@class="vd_bt_v2 vd_page_btn"]'))
)
for page_selector in page_selectors:
next_text = page_selector.find_element_by_xpath('./span').text.strip()
if next_text == '下一页':
next_url = page_selector.get_attribute('href')
self.search_info_by_url(next_url)
def main(self):
self.search_info_by_url(self.baseurl)
self.driver.close()
return self.items
class Load(object):
def __init__(self, item):
self.item = item
self.driver = webdriver.Chrome()
self.driver.maximize_window()
self.waiter = WebDriverWait(self.driver, 5)
def run(self):
title, url = self.item
self.driver.get(url)
load_button = self.waiter.until(
EC.presence_of_element_located((By.XPATH, '//*[@id="download_big_btn"]'))
)
# 点击下载歌曲的按钮,自动下载到本地
load_button.click()
print('{} is loading, the url is {}'.format(title, url))
time.sleep(20)
def close(self):
self.driver.close()
def run(item):
L = Load(item)
L.run()
L.close()
def main(items):
with ThreadPoolExecutor(max_workers=4) as pool:
pool.map(run, items)
if __name__ == '__main__':
url = 'https://vdisk.weibo.com/s/tg6IJ27yogat5'
wp = Weipan(url)
items = wp.main()
main(items)
源码解读
首先,代码中有两个下载类和两个函数,其中 Weipan 类的作用就是使用递归的方式进行歌曲下载页地址的提取,这里在定位元素位置的时候都使用的是 WebDriverWait 智能等待,这个等待可以在节约时间的同时做到避免短时间内定位不到元素而报错。
使用 get_attribute() 方法可以提取当前元素的属性,比如这里提取了当前标签的 href 和 title 属性,对应了歌曲的下载页地址和歌曲文件名称,这里使用元组的形式报错到列表中。
分页的代码主要是下面这一段,使用了递归:
for page_selector in page_selectors:
next_text = page_selector.find_element_by_xpath('./span').text.strip()
if next_text == '下一页':
next_url = page_selector.get_attribute('href')
self.search_info_by_url(next_url)
当第一个提取到所有歌曲的下载页地址完成之后,使用多线程的形式开始多个线程同时下载歌曲,这里使用了 python3 独有的多线程类 ThreadPoolExecutor
首先看一下下载单个歌曲的类是 Load 这个类接受一个元组,其实也就是之前提取到的下载地址和标题。这个类做的事情很简单,就是打开一个浏览窗口,然后定位到下载按钮,触发点击操作,然后关闭浏览器。这一整个操作被写入到了一个函数中,也即是:
def run(item):
L = Load(item)
L.run()
L.close()
这样做的目的是为了后续使用多线程的时候更方便直观一些。多线程的线程数量可以自己定,我这里设置了最多4个线程,也即是最多开启4个浏览器窗口(这个根据自己电脑情况还有网速来设置,看CPU够不够用吧),看一下多线程的使用,是不是非常简单,我真的是非常喜欢这个多线程类,使用起来非常方便:
def main(items):
with ThreadPoolExecutor(max_workers=4) as pool:
pool.map(run, items)
代码弊端
看上面点击下载按钮之后,我这里设置了一个等待时间,设置的是20秒,这个等待时间就是下载每个歌曲的时间,其实一个歌曲大概4M左右,如果是4个窗口同时下载的话,约等于16M的下载量,如果网速是1M的话,要花费16秒,但是计算结果肯定跟实际有差别,所以我这里设置的是20秒等待时间,为了保证足够的时候给浏览器去下载,下载时间到了才会关闭浏览器开启新的下载。
正因为无法预测每个歌曲的实际下载时间,有的很快,有的很慢,所以难免有的页面歌曲下载20秒还没有下载完成,所以这种情况会导致有些歌曲根本没有下载完整,这个问题无法直接避免,只能通过适当的调整等待时间来减少。
正因为发现了这个问题,所以才让我继续思考了不使用 selenium 来下载歌曲的方式,这个后续单独分享文章讲解。
运行结果
代码执行
代码执行的时候,可以看到类似如下的:
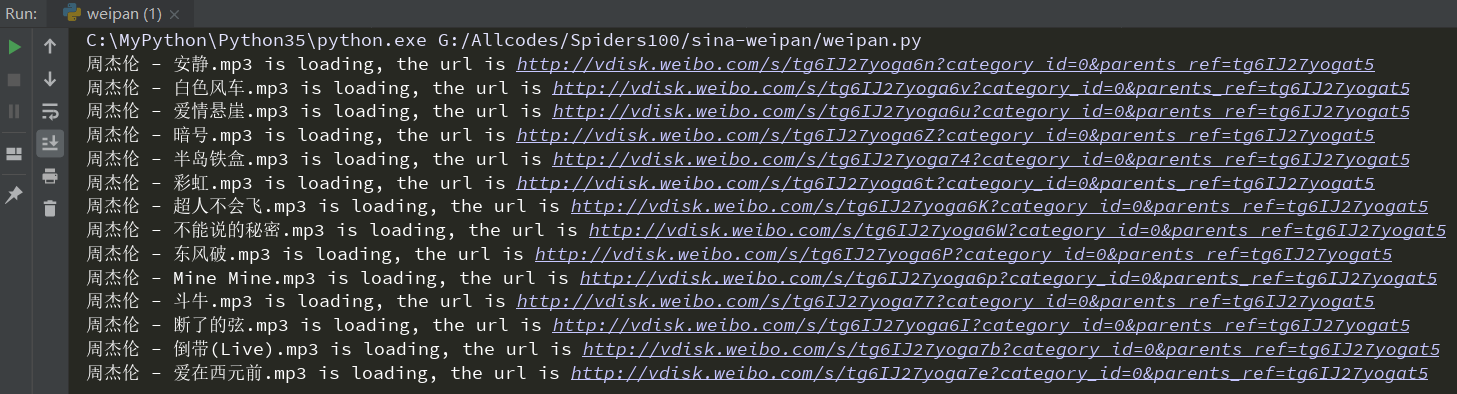
歌曲下载结果
可以看到,已经出现了我上面提到的问题,有两首歌曲由于文件没有下载完浏览器就关闭了,所以歌曲并没有下载完整。
音频处理
为什么有音频处理?因为我发现下载到的歌曲都被人在歌曲开头加了一段广告语言,大概有9秒钟,所以听歌会有广告,这个怎么能忍?所以下载完成的音频需要批量进行剪切处理。
音频处理使用 pydub 库(临时学一下怎么使用这个库即可,不用深入研究),这个库依赖 ffmpeg 或者 libav
安装完依赖之后,需要把依赖的软件 bin 目录添加到环境变量 Path 中,比如我下载了 ffmpeg ,然后需要把 D:\Program Files (x86)\ffmpeg\bin 添加到环境变量中。
然后可以安装 pydub,使用 pip 命令即可:
pip install pydub
安装完依赖就可以写个脚本批量处理音频了,我这里是进行剪切处理,就是减掉每个 mp3 文件的前9秒,脚本代码如下:
# -*- coding:utf-8 -*-
# Author: https://github.com/Hopetree
# Date: 2019/8/10
'''
剪切音频的工具
'''
import os
from pydub import AudioSegment
def cut_mp3(dirname):
for each in os.listdir(dirname):
_name, _type = os.path.splitext(each)
filename = os.path.join(dirname, each)
newdir = os.path.join(dirname, 'new')
if not os.path.exists(newdir):
os.makedirs(newdir)
newname = os.path.join(newdir, each)
if _type == '.mp3':
mp3 = AudioSegment.from_mp3(filename)
new_mp3 = mp3[9 * 1000:]
new_mp3.export(newname, format='mp3')
print('{} cut done'.format(each))
if __name__ == '__main__':
DIRNAME = r'C:\Users\HP\Downloads\load'
cut_mp3(DIRNAME)
参考文章:
版权声明:如无特殊说明,文章均为本站原创,转载请注明出处
本文链接:https://tendcode.com/subject/article/python-spider-sina-weipan/
许可协议:署名-非商业性使用 4.0 国际许可协议
duanrungang
1 楼 - 5 年,8月前
博主你好,你的文章写的真好,对我很有帮助!!非常感谢!