今天是11月11,也就是电商狂欢日,本该守着点开始抢购商品的,但是由于自己本身也没有想买的东西,而且之前也做过电商公司的数据爬取工作,所以闲的没事就在别人都在网购的时候,自己趁机写了个小爬虫来爬取天猫店铺的商品信息。
爬虫思路
前几天我刚写了一个文章是关于安装 scrapy 的,正好装好了,于是就选择了强大的 scrapy 爬虫框架作为爬虫的工具。
确定方向
首先,在写爬虫之前,需求先确定一下爬虫的方向,也就是回答几个问题:
- 需要爬取什么信息?
- 信息的来源是哪里?
- 有没有其他来源?有的话,选择最简单的那个。
- 怎么爬?信息怎么存储?
我写这个爬虫之前已经经过一番思索和网站分析之后得到了结论:
- 爬的信息是天猫某个店铺的所有商品的基本信息,比如爬取优衣库全店的商品基本信息
- 信息来源主要分为2个地方,一个是天猫 PC 版,第二个就是手机天猫,而经过对比发现手机天猫提取信息的接口比较方便,所以选择手机天猫的接口
- 使用爬虫框架 scrapy,信息存放到表格中,使用 CSV 的表格即可
接口分析
写爬虫其实本质就是请求接口,所以爬虫的第一步就是找到接口并分析接口的构成。而经过我的对比分析,发现手机天猫(m.tmall.com)的接口比天猫 PC 版(tmall.com)的接口简单,所以选择了手机版的接口。
首先,通过将网页设置成手机浏览模式,天猫的域名就会自动切换成手机接口。进入某个天猫店铺,然后选择“所有商品”,然后模拟手机的滑动屏幕操作,刷新屏幕,这样就能看到网站调用了什么接口,具体分析过程可以看截图:
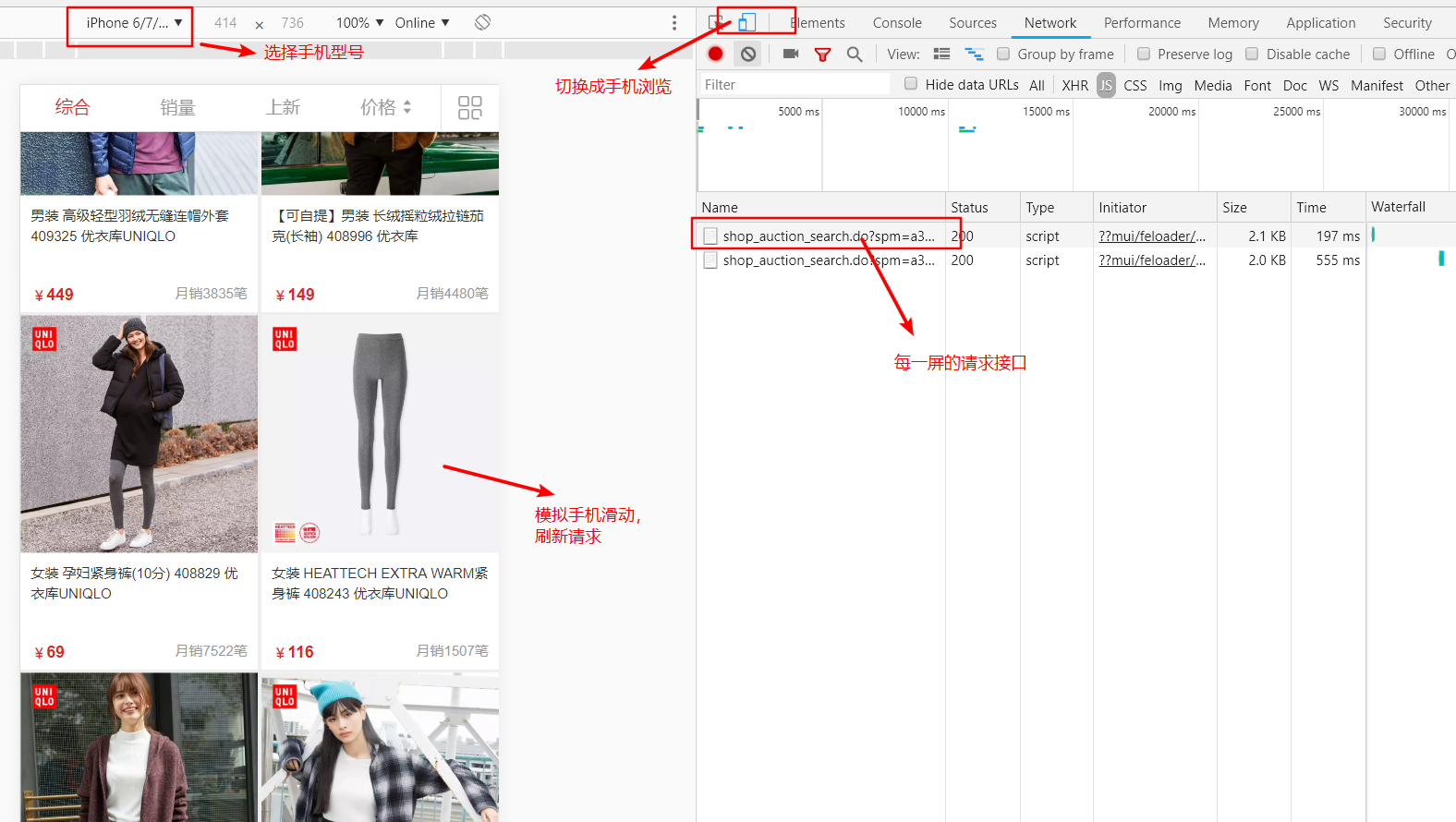
拿到了接口之后,事情并没有完,还需要分析接口的具体构成,这个分析过程就要靠经验了,这里不做过多的阐述。
信息存储
这里为了方便又简单的存储数据,所以直接考虑使用 Python 自带的模块 csv 模块将数据存储为表格的形式。
源码分析
项目结构
首先,使用 scrapy 的项目创建命令就可以生成一个标准的项目结构目录,而我下面列出来的文件只是比基础目录多了一个 data 目录和 tm_spiders.py 文件。
+----ECspiers
| +----data
| | +----macys.csv
| | +----muji.csv
| | +----uniqlo.csv
| | +----veromoda.csv
| +----items.py
| +----middlewares.py
| +----pipelines.py
| +----settings.py
| +----spiders
| | +----tm_spiders.py
| | +----__init__.py
| +----__init__.py
+----scrapy.cfg
文件介绍
- data 目录是自己创建的,用来存放爬到的数据
- items.py 是项目自己生成的,用来定义要爬取的字段
- middlewares.py 是请求中间件,一般是用来处理请求的,可以不用
- pipelines.py 是用来处理爬到的信息的,当然,也可以不用在这里处理
- settings.py 是爬虫的配置文件,可以根据需要定义一些参数
- spiders 目录是用来放爬虫文件的
- tm_spiders.py 是自己创建的爬虫文件
- scrapy.cfg 是项目的配置文件
爬虫代码展示
其实整个的爬虫爬取信息的过程都在自己定义的爬虫文件中,源码如下:
# -*- coding:utf-8 -*-
import scrapy
from scrapy.conf import settings
from ..items import EcspiersItem
from urllib import parse
import time
import re
import json
class TMSpider(scrapy.Spider):
name = 'tmall_m'
allowed_domains = ["tmall.com"]
start_urls = [
'https://m.tmall.com'
]
def parse(self, response):
for shop_domain in settings['TMALL_SHOP_DOMAINS']:
url = 'https://{0}.m.tmall.com/shop/shop_auction_search.do'.format(shop_domain)
params = {
'sort': 's',
'p': 1,
'from': 'h5',
'ajson': 1,
'_tm_source': 'tmallsearch',
'callback': 'json{}'.format(time.time())
}
url = '{0}?{1}'.format(url, parse.urlencode(params))
yield scrapy.Request(url, callback=self.parse_get_items, meta={'shop_domain': shop_domain})
def parse_get_items(self, response):
shop_domain = response.meta['shop_domain']
data = re.findall('json.*?\(({.*})\)', response.text)
if data:
data = json.loads(data[0])
items = data.get('items')
if items:
for each in items:
item_id = each.get('item_id')
params = {
'itemId': item_id,
'callback': 'json{}'.format(time.time())
}
url = 'https://dsr-rate.tmall.com/list_dsr_info.htm?{}'.format(parse.urlencode(params))
yield scrapy.Request(url, callback=self.parse_get_dsr, meta={'each_item': each})
total_page = data.get('total_page')
current_page = data.get('current_page')
if total_page and current_page:
if int(current_page) < int(total_page):
print('当前爬取页码是>>>>>>>>>>>>>>>>>>>>>', current_page)
next_page = int(current_page) + 1
url = 'https://{0}.m.tmall.com/shop/shop_auction_search.do'.format(shop_domain)
params = {
'sort': 's',
'p': next_page,
'from': 'h5',
'ajson': 1,
'_tm_source': 'tmallsearch',
'callback': 'json{}'.format(time.time())
}
url = '{0}?{1}'.format(url, parse.urlencode(params))
yield scrapy.Request(url, callback=self.parse_get_items, meta={'shop_domain': shop_domain})
def parse_get_dsr(self, response):
each = response.meta['each_item']
data = re.findall('json.*?\(({.*})\)', response.text)
if data:
data = json.loads(data[0])
dsr = data.get('dsr').get('gradeAvg')
each['dsr'] = dsr
item = EcspiersItem()
for key in settings['TMALL_ITEM_TITLE']:
item[key] = each.get(key)
yield item
scrapy 的具体的使用方法其实看官方的一些文档会更加容易理解,所谓的举一反三即可,所以这里就不做过多的解释。
我简单描述一下自己的爬虫的逻辑:首先构造接口请求,然后请求获取到商品的一些信息(当获取到商品 ID 之后,我为了进一步获取商品的 dsr 信息所以单独去请求了一下另一个接口,dsr:商品评分),然后根据请求的信息中页码总数,构造一个循环,迭代增加当前页去请求即可。
项目地址
项目所有代码已经上传到 GitHub 上面 爬虫源码
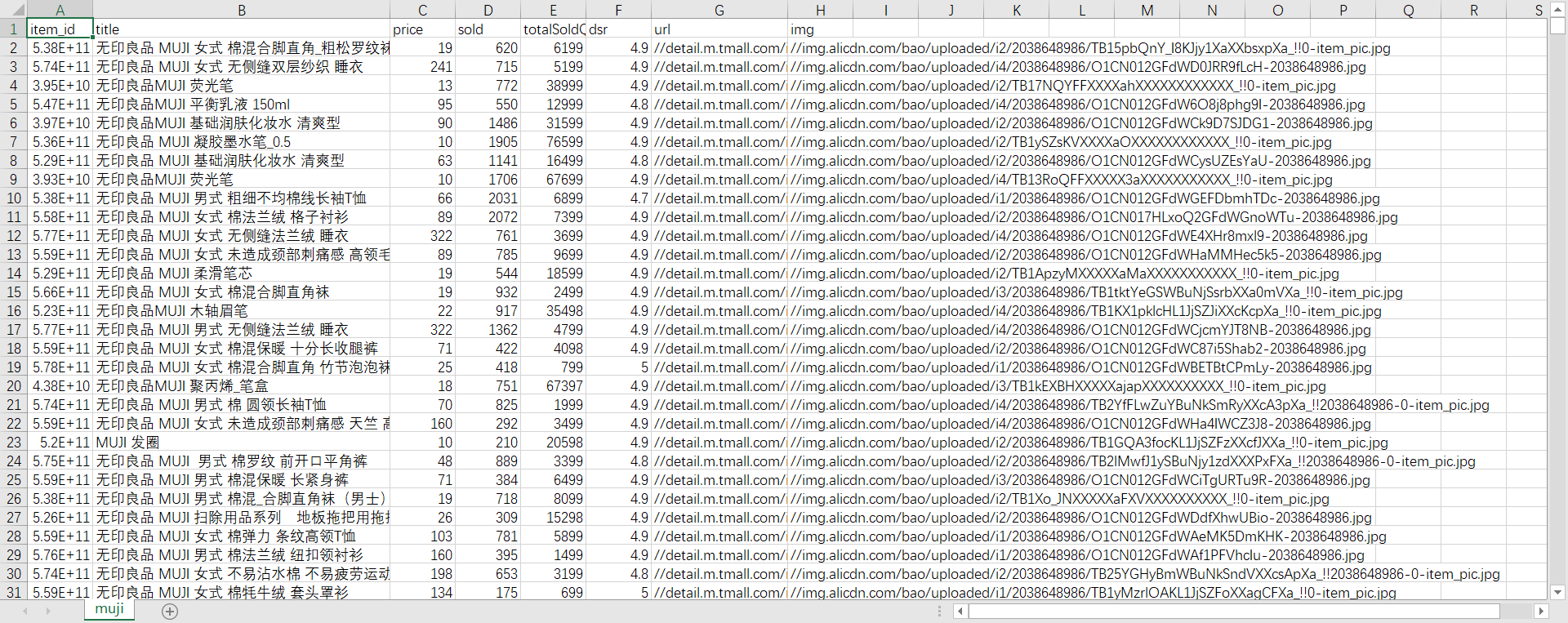
信息展示
爬到的信息保存为 csv 的表格形式,看截图:
一个脚本分享
为了这个文章里面输出一个目录树,我单独写了一个脚本来生成目录树。虽然说 Windows 的命令行有 tree 可以直接输出目录树,但是并不能达到我想要屏幕指定目录文件的要求,所以还是自己动手丰衣足食吧!
# -*- coding:utf-8 -*-
# date:2018-11-12
import os
class FileTree(object):
def __init__(self, words=[]):
self.TAG_Y = "| "
self.TAG_X = "+----"
self.IGNORE_WORDS = words
def print_tree(self, dirname, depth=0):
if os.path.isdir(dirname):
for item in os.listdir(dirname):
if item not in self.IGNORE_WORDS:
print(self.TAG_Y * depth + self.TAG_X + item)
child = os.path.join(dirname, item)
if os.path.isdir(child):
self.print_tree(child, depth + 1)
else:
print('"{}" is not a folder'.format(dirname))
if __name__ == '__main__':
dirname = r'G:\Mycodes\ECspiers'
c = FileTree(['__pycache__'])
c.print_tree(dirname)
版权声明:如无特殊说明,文章均为本站原创,转载请注明出处
本文链接:https://tendcode.com/subject/article/tmall-scrapy-spider/
许可协议:署名-非商业性使用 4.0 国际许可协议










影灵衣丶
12 楼 - 5 年,9月前
文章很有用