前言
我经常有下载电视剧的需求,一般会去资源网站找迅雷下载地址,而有的网站的下载地址要一个一个点击才能下载,遇到集数多的剧就很麻烦,于是我衍生了一个小需求就是希望直接提取网页源码中的下载地址进行复制。
基于此,我产生了开发一个简单的浏览器插件来进行这个操作,于是利用周末的时间,在我几乎没有写一行代码的情况下,我完全靠提问的形式让 ChatGPT 给我开发了一个完全满足我需求的完整浏览器插件项目,本文分享一下这个浏览器插件项目。
我的需求
基本需求
由于我完全没有开发浏览器插件的经验,而且最初的需求也很简单,于是我最初只是告知 ChatGPT 我的基本需求:
我想要开发一个浏览器插件,我希望这个插件可以支持目前主流的浏览器,这个插件的主要功能是使用正则表达式提取网页源码中的内容,我希望能够有个界面让用户输入正则表达式,并且可以一键复制提取的结果。
基于这个基本的需求,ChatGPT 很快给我提供了一个插件项目的代码结构和相关代码,并且经过指导,我很快就将插件运行起来了,经过一些调试和修改,效果如下:
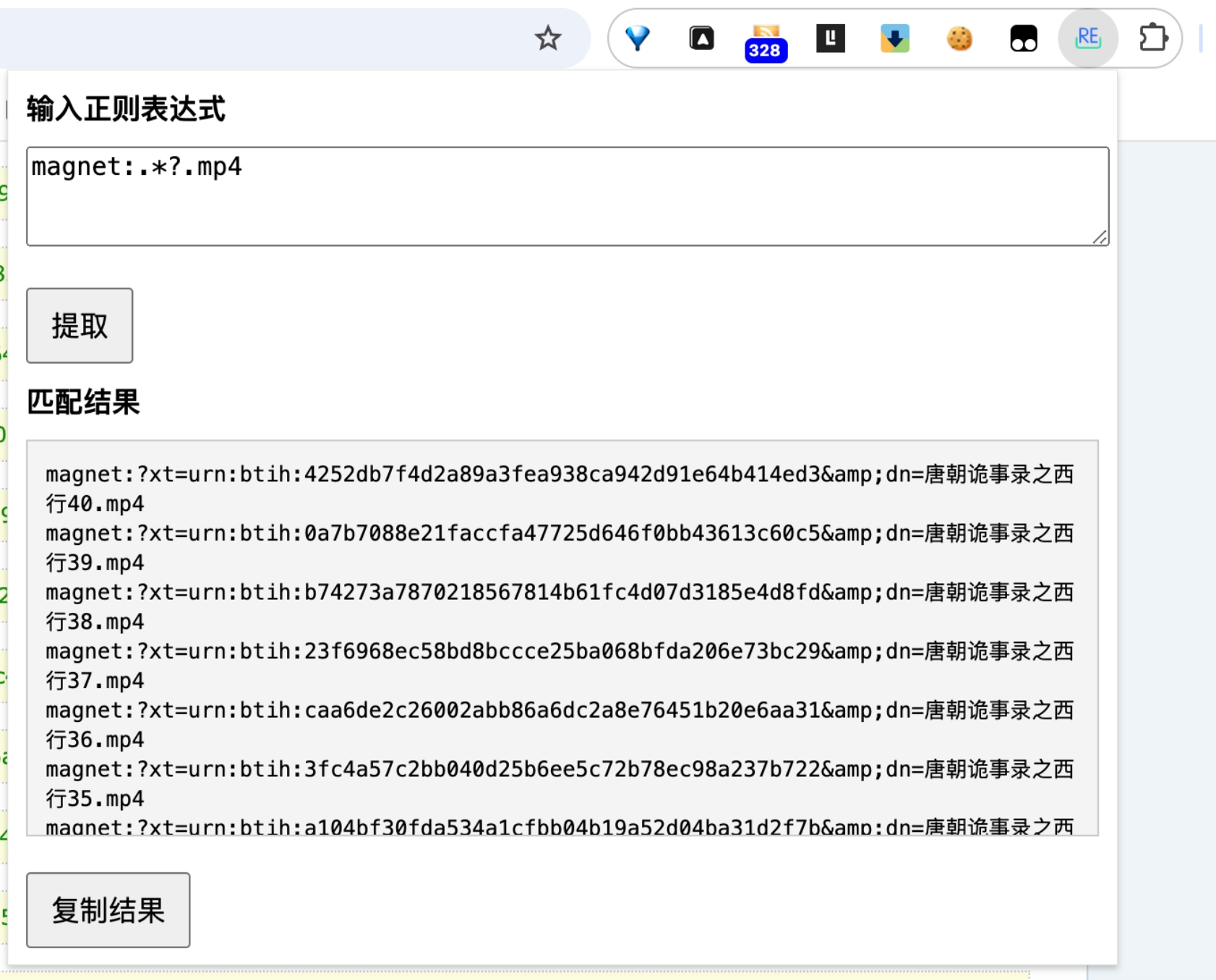
可以说效果还是非常不错的,完全满足我的基本需求!
增删改查的需求
实现了基本需求之后,我又想到了应该给插件添加增删改查功能,用户可以在本地添加一些常用的正则表达式,方便后续直接选择使用,于是经过我的设计,我需要有两个页面,一个是操作页面另一个是管理页面,经过几个迭代,最终的效果如下:
这是主页面,用来提取内容,这里用户可以直接输入正则也可以从本地保存的正则中选择一个正则进行提取,并且会显示匹配的结果个数:
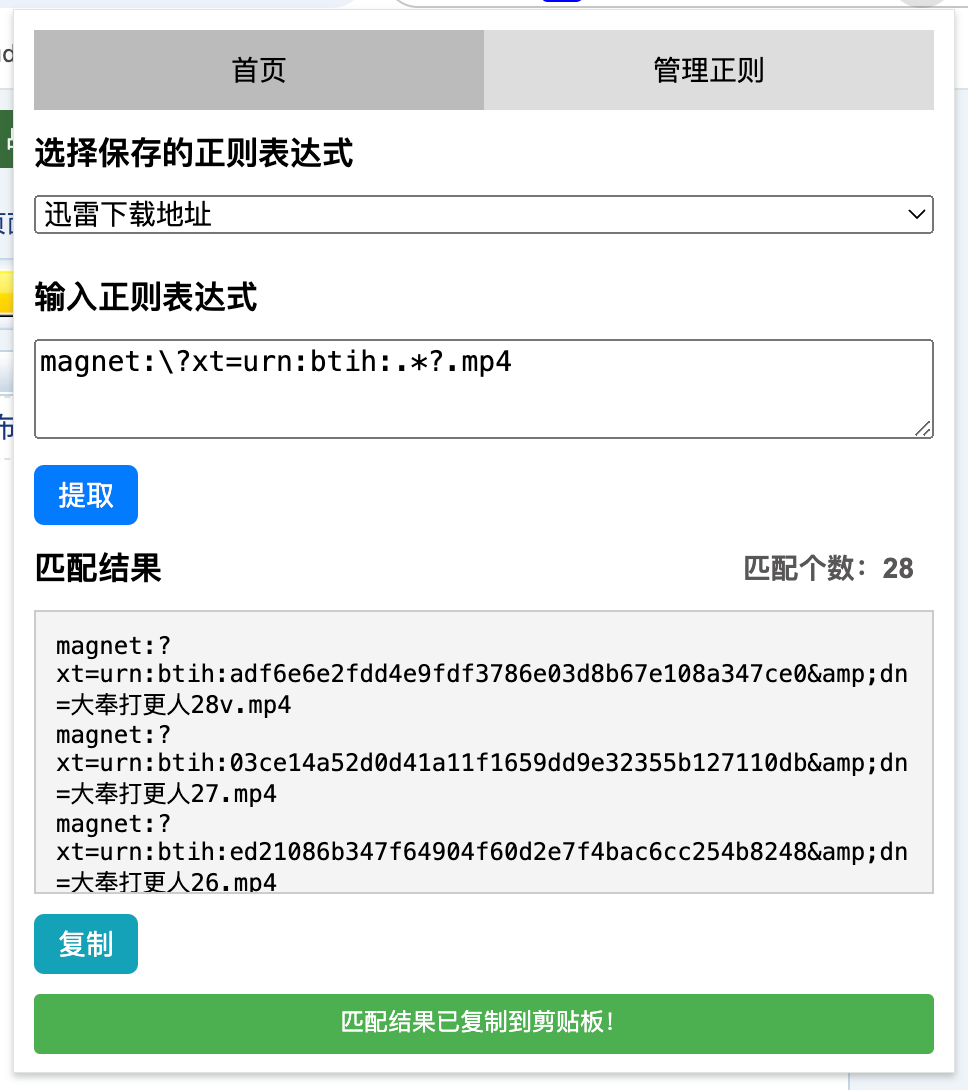
这个是管理页面,用来对本地正则进行增删改查:

当然,由于需求相对复杂一点,目前的最终效果达成之前其实还是遇到很多 Bug,比如保存的时候经常分不清是新增还是更新,就这一个 Bug 就调了好几次才搞定。
插件项目介绍
这是我第一个开发浏览器插件项目,虽然我几乎没有写一行代码(说几乎是因为我单独写过一些样式代码,比如按钮的样式参考的 bootstrap 的按钮样式改的),但是从 ChatGPT 开发的过程和项目结构我大概也能知道浏览器插件要如何开发。
项目结构
完整的项目我已经开源到 github 上面,具体见:PageScraper
整个项目的结构如下:
├── LICENSE
├── README.md
├── content.js
├── icons
│ ├── icon128.png
│ ├── icon16.png
│ └── icon48.png
├── main.css
├── manifest.json
├── popup.html
└── popup.js
manifest.json 文件
插件的主要文件是 manifest.json 文件,这个相当于插件的定义文件,有固定的一些格式,我的文件内容如下:
{
"manifest_version": 3,
"name": "正则提取页面内容",
"version": "2.0",
"description": "从当前页面源码中提取匹配的内容。",
"permissions": ["activeTab", "scripting"],
"icons": {
"16": "icons/icon16.png",
"48": "icons/icon48.png",
"128": "icons/icon128.png"
},
"action": {
"default_popup": "popup.html",
"default_icon": {
"16": "icons/icon16.png",
"48": "icons/icon48.png",
"128": "icons/icon128.png"
}
},
"content_scripts": [
{
"matches": ["<all_urls>"],
"js": ["content.js"]
}
]
}
这个文件用来定义插件的一些基本信息,比如名称、版本、icons 还有界面文件等,不过其中定义的 content.js 我是没有用到的,所以这个文件是一个空文件。
popup.html 文件
这个文件就是插件的界面,具体内容可见我项目代码:https://github.com/Hopetree/PageScraper/blob/main/popup.html
这个文件的内容就是一个很基本的 HTML 文件,可以按照一般的常规网页开发来做,并且可以在本地进行调试。
静态资源文件
静态资源文件包括逻辑处理文件 popup.js 和样式文件 main.css,其中逻辑处理文件是 ChatGPT 最开始就定义好的,可能是因为逻辑处理代码比较多,所以分离成一个单独的文件,而样式文件是我最后自己提要求让 ChatGPT 抽离出来的,因为随着项目的进行,样式要求越来越多,写到 HTML 文件中不方便管理和维护。
最后就是 icons 文件,这些文件是我从阿里的图标库下载的。
项目调试
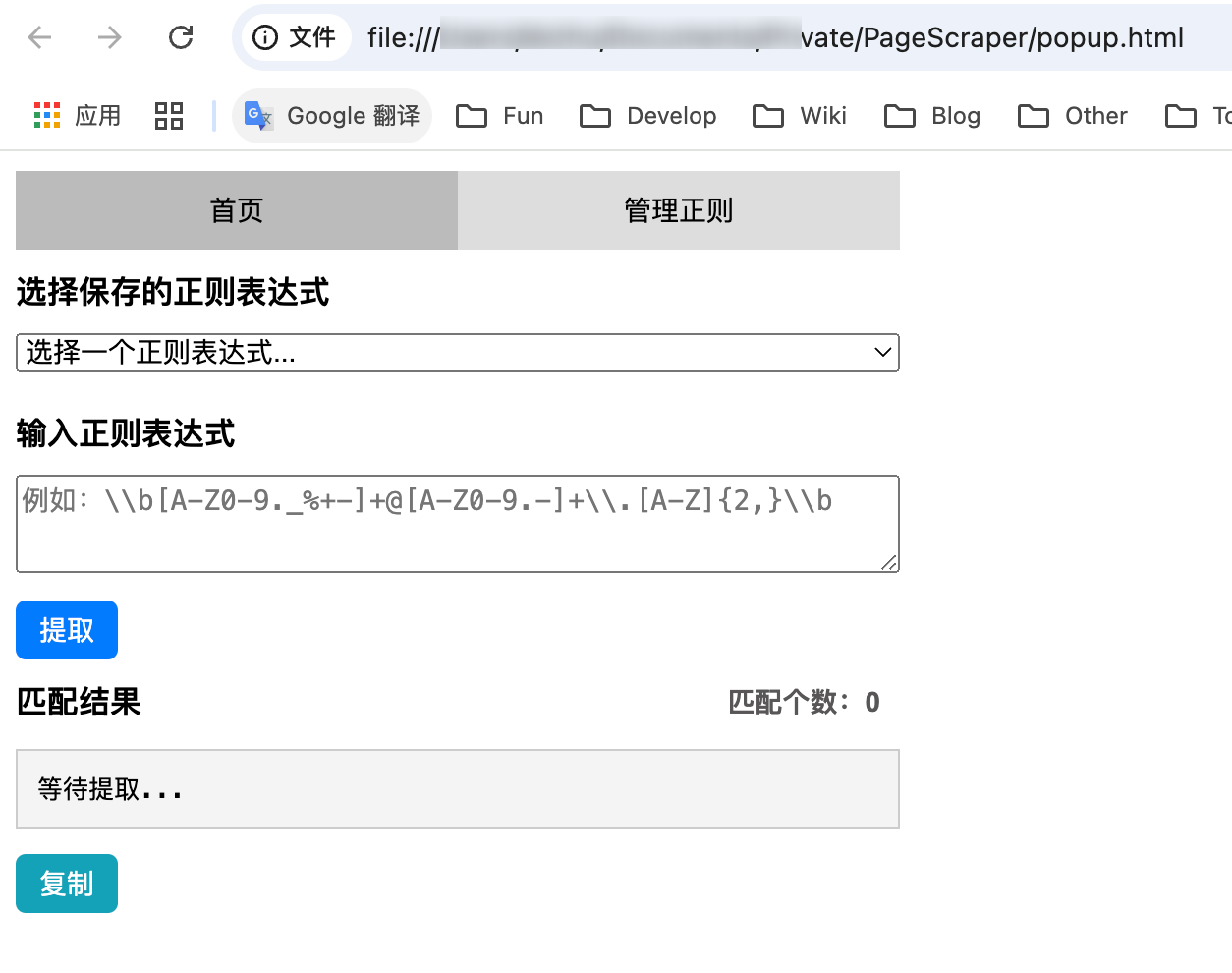
其实一个浏览器插件的本质也是一个网页,特别是我这种插件,并不需要跟目标网页进行动态联动,所以完全可以直接调试。
直接在本地打开 popup.html 文件就可以看到插件的页面,也可以直接进行操作,效果如下:
安装插件
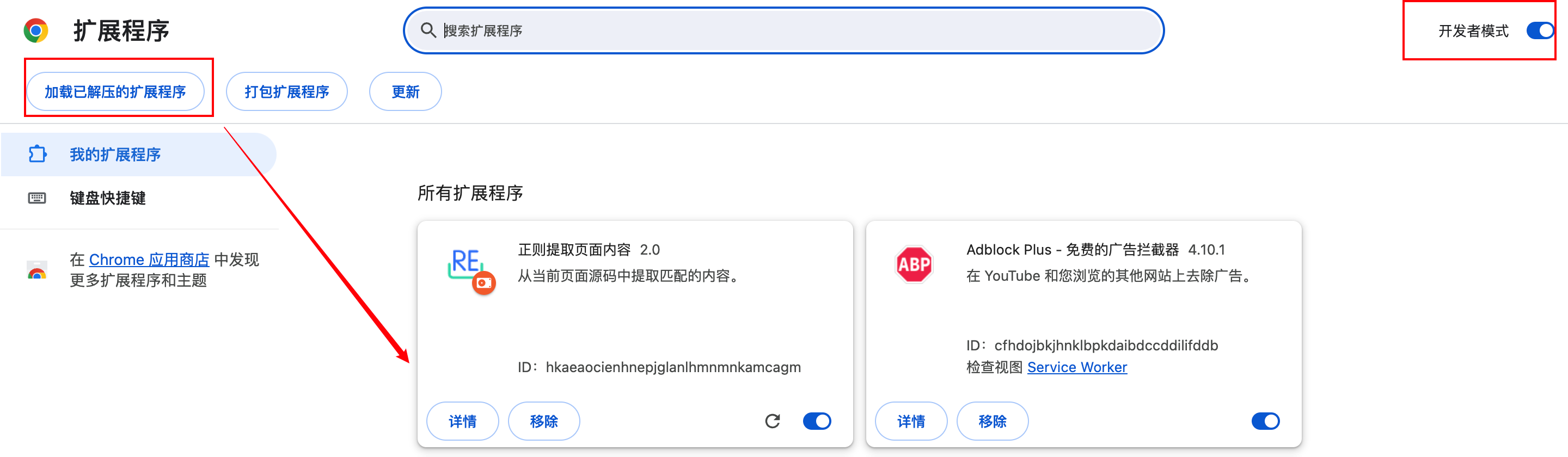
插件开发完成之后,直接到浏览器的扩展中加载项目目录就行,加载完成就可以使用插件了,并且本地插件进行任何调试都会更新到插件中不需要额外进行操作。
总结
经过这次的浏览器插件开发经验,我已经对浏览器插件的开发有一定的了解,特别是知道了原来所谓的插件的本质也是一个网页,完全可以当做一个独立的网页项目来开发。后续我有好的想法的话,说不定会考虑给我的博客项目开发一个浏览器插件扩展来进行一些有意思的操作。
版权声明:如无特殊说明,文章均为本站原创,转载请注明出处
本文链接:https://tendcode.com/subject/article/develop-browser-plugin-with-chatgpt/
许可协议:署名-非商业性使用 4.0 国际许可协议