之前写了一篇使用 selenium 爬取新浪微盘上面周杰伦的歌曲的文章,当时是因为有个接口的构造方式没有分析出来,所以才使用了 selenium 模拟浏览器进行下载,但是模拟浏览器下载歌曲遗留了一个问题,所以后来自己还是继续分析各个接口,最终把所有接口调通了。
接口分析
跟之前使用 selenium 的时候分析页面一样,分析接口也是同样的思路,要想下载歌曲资源,需要调用以下接口:
- 列表页资源查询接口,提取每个资源的下载页链接,同时需要进行翻页操作
- 资源页面接口调用,获取资源查询接口的构造参数
- 资源接口调用,获取下载信息
下面就按照上面的三个接口来写爬虫
列表页
列表页的接口其实就是当前列表页的地址,请求也没有什么特殊要求,请求头都不需要设置,请求完成之后直接使用 xpath 来提取资源页面的请求地址即可,这个思路跟 selenium 的请求一样。
资源接口
在资源页点击下载按钮的时候会直接进行资源下载,这个时候应该开启 F12 查看接口调用,会发现调用了一个如下截图的接口:
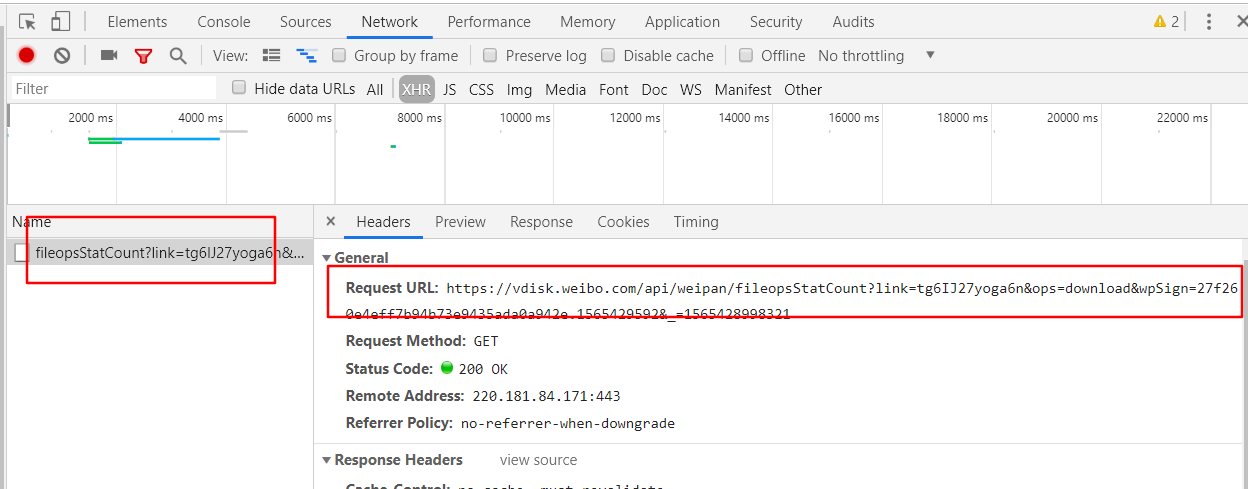
然后查看一下这个接口的返回信息,可以看到接口里面就有资源的下载地址,所以很显然,只要构造出这个接口并进行请求就可以得到资源下载链接了:
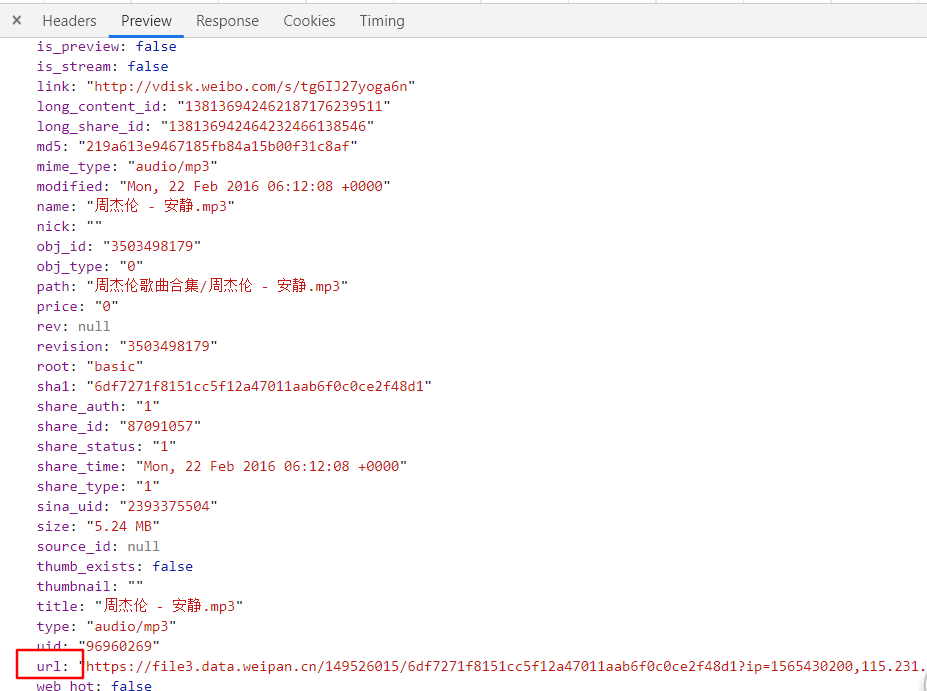
资源接口构造
资源接口的格式是这样的:
https://vdisk.weibo.com/api/weipan/fileopsStatCount?link=tg6IJ27yoga6v&ops=download&wpSign=f689970c3df5e591921751352c169a27.1565502781&_=1565502185086
解析一下接口的参数,会发现总共需要以下参数:
- link:这个参数相当于当前资源的 ID,这个可以从当前页的 url 中提取,当然也可以直接到页面中提取(后续提到)
- ops:这个参数是固定的 download
- wpSign:这个参数是一个动态变动的,而且没有任何规律,所以这个参数才是构造接口的关键,如何获取到这个参数是爬虫的关键所在
- _:这个参数一看就知道是时间戳,不解释
这个接口除了需要构造出接口之外,在请求的时候我还遇到了问题,虽然是个 GET 请求,但是直接进行请求的话,会返回 “invalid source”,这就尴尬了,一开始我还以为是进行了什么比较复杂的反爬措施,毕竟是网盘服务,加强反爬也是理所当然,但是后来我发现其实只需要在请求头中添加 Referer 即可,这个请求头参数其实也比较常见,就是接口的跳转地址,这个可以直接设置为当前页的地址。
源码解析
接口都分析清楚了,现在就可以开始写爬虫了,先贴一下爬虫源码:
# -*- coding:utf-8 -*-
# Author: https://github.com/Hopetree
# Date: 2019/8/10
'''
新浪微盘资源下载,不需要模拟浏览器,完全使用接口调用
'''
import os
import re
import time
import json
from concurrent.futures import ThreadPoolExecutor
import requests
from lxml import etree
class Weipan(object):
def __init__(self, url, output):
self.baseurl = url
self.items = []
self.output = output
def get_item_list(self, url):
res = requests.get(url).text
tree = etree.HTML(res)
# 提取当前页所有资源,存入列表
item_selectors = tree.xpath('//div[@class="sort_name_intro"]/div/a')
for item_selector in item_selectors:
link = item_selector.get('href')
title = item_selector.get('title')
self.items.append((link, title))
# 提取下一页链接,进行递归爬取
next_page_selectors = tree.xpath('//div[@class="vd_page"]/a[@class="vd_bt_v2 vd_page_btn"]')
for next_page_selector in next_page_selectors:
next_text = next_page_selector.xpath('./span')[0].text.strip()
if next_text == "下一页":
next_url = self.baseurl + next_page_selector.get('href')
self.get_item_list(next_url)
def get_callback_info_by_item(self, item):
'''
提取一个资源页面的有效信息,用来构造请求url
'''
url, title = item
res = requests.get(url).text
id = re.findall("CURRENT_URL = 'vdisk.weibo.com/s/(.*?)'", res)[0]
sign = re.findall("SIGN = '(.*?)'", res)[0]
url_temp = 'https://vdisk.weibo.com/api/weipan/fileopsStatCount?link={id}&ops=download&wpSign={sign}&_={timestr}'
timestr = int(time.time() * 1000)
callback = url_temp.format(id=id, sign=sign, timestr=timestr)
return url, callback
def get_load_info_by_callback_info(self, callback_info):
'''
请求回调地址,返回资源下载地址等信息
'''
url, callback = callback_info
headers = {
'Referer': url,
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:45.0) Gecko/20100101 Firefox/45.0'
}
res = requests.get(callback, headers=headers).text
data = json.loads(res)
name = data.get('name')
load_url = data.get('url')
return name, load_url
def load(self, load_info):
name, load_url = load_info
content = requests.get(load_url).content
savename = os.path.join(self.output, name)
with open(savename, 'wb+') as f:
f.write(content)
print('{} load done'.format(name))
def load_by_item(self, item):
'''
线程执行的函数
'''
callback_info = self.get_callback_info_by_item(item)
load_info = self.get_load_info_by_callback_info(callback_info)
self.load(load_info)
def main(self):
# 收集资源下载信息
self.get_item_list(self.baseurl)
# 多线程下载资源
with ThreadPoolExecutor(max_workers=8) as pool:
pool.map(self.load_by_item, self.items)
if __name__ == '__main__':
URL = 'https://vdisk.weibo.com/s/tg6IJ27yogat5'
OUTPUT = r'C:\Users\HP\Downloads\load'
wp = Weipan(URL, OUTPUT)
wp.main()
获取资源页地址
获取资源页地址的方式就是请求列表页,然后从 HTML 中提取链接地址,当然,还是翻页,翻页的思路还是递归,具体代码如下:
def get_item_list(self, url):
res = requests.get(url).text
tree = etree.HTML(res)
# 提取当前页所有资源,存入列表
item_selectors = tree.xpath('//div[@class="sort_name_intro"]/div/a')
for item_selector in item_selectors:
link = item_selector.get('href')
title = item_selector.get('title')
self.items.append((link, title))
# 提取下一页链接,进行递归爬取
next_page_selectors = tree.xpath('//div[@class="vd_page"]/a[@class="vd_bt_v2 vd_page_btn"]')
for next_page_selector in next_page_selectors:
next_text = next_page_selector.xpath('./span')[0].text.strip()
if next_text == "下一页":
next_url = self.baseurl + next_page_selector.get('href')
self.get_item_list(next_url)
跟 selenium 的时候基本是一模一样的提取方式和翻页方式,而且可以使用同样的 xpath 语法,代码量不大。
构造资源请求接口
之前分析接口的时候已经说到了,资源请求接口是需要用参数构造的,其实比较没有规律的参数是 wpSign ,这个参数其实可以从资源页面中提取,具体代码如下:
def get_callback_info_by_item(self, item):
'''
提取一个资源页面的有效信息,用来构造请求url
'''
url, title = item
res = requests.get(url).text
id = re.findall("CURRENT_URL = 'vdisk.weibo.com/s/(.*?)'", res)[0]
sign = re.findall("SIGN = '(.*?)'", res)[0]
url_temp = 'https://vdisk.weibo.com/api/weipan/fileopsStatCount?link={id}&ops=download&wpSign={sign}&_={timestr}'
timestr = int(time.time() * 1000)
callback = url_temp.format(id=id, sign=sign, timestr=timestr)
return url, callback
其中 link 参数和 wpSign 参数都是使用正则表达式从资源页的 HTML 中提取,可以看一下网页源代码中的信息:
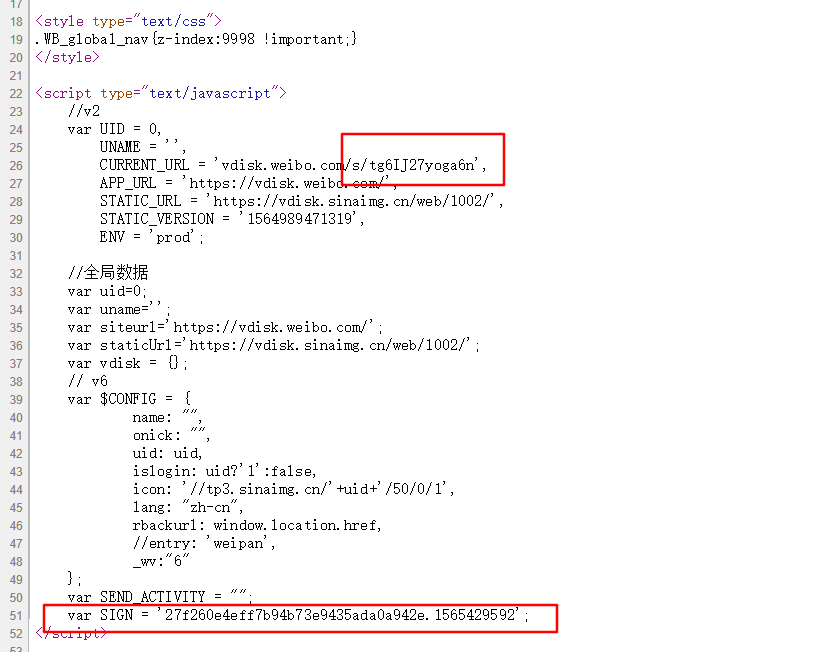
参数都提取到之后,就可以构造出请求接口了,最后可以通过函数返回接口地址,同时可以把当前的页面地址也返回,因为这个可以当做 Referer 的值传递到请求头中。
提取下载信息
构造出请求接口之后就可以开始调用接口,具体代码如下:
def get_load_info_by_callback_info(self, callback_info):
'''
请求回调地址,返回资源下载地址等信息
'''
url, callback = callback_info
headers = {
'Referer': url,
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:45.0) Gecko/20100101 Firefox/45.0'
}
res = requests.get(callback, headers=headers).text
data = json.loads(res)
name = data.get('name')
load_url = data.get('url')
return name, load_url
这个函数其实听简单的,就是一个普通的接口调用,只是需要带上请求头而已
多线程下载
由于网页请求和资源下载都属于 I/O 密集型的,所以选择使用多线程操作可以有效提升效率。
下载单个资源的函数是下面这个:
def load_by_item(self, item):
'''
线程执行的函数
'''
callback_info = self.get_callback_info_by_item(item)
load_info = self.get_load_info_by_callback_info(callback_info)
self.load(load_info)
所以多线程的时候这个函数就是回调函数,而参数就是所有的资源信息,多线程依然可以使用 ThreadPoolExecutor:
def main(self):
# 收集资源下载信息
self.get_item_list(self.baseurl)
# 多线程下载资源
with ThreadPoolExecutor(max_workers=8) as pool:
pool.map(self.load_by_item, self.items)
爬虫结果
之前使用 selenium 的时候,说到在下载歌曲的时候有个问题无法解决,那就是浏览器下载一个歌曲的时间是无法准确预测的,所以当等待时间过短的时候可能导致文件没有下载完成就关闭了浏览器,而如果时间设置过长又浪费时间。但是这里使用接口调用就不会有任何这方面的问题,因为下载资源只有结束线程才会结束。
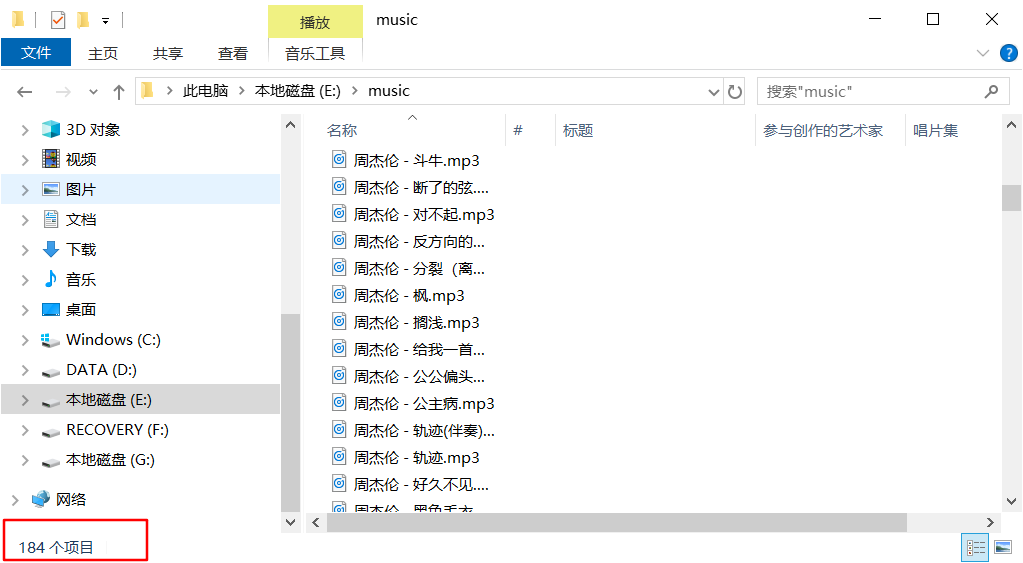
下载的歌曲总共有184首,看看结果,正好184首歌曲,全部是完整的,而且效率也挺快的,完全可以充分利用带宽,不会浪费一秒钟。
版权声明:如无特殊说明,文章均为本站原创,转载请注明出处
本文链接:https://tendcode.com/subject/article/python-spider-sina-weipan-2/
许可协议:署名-非商业性使用 4.0 国际许可协议






qwert12
7 楼 - 2 年,12月前
good