周末在家花了一点时间给网站加了一些可视化报表,除了一些关于阅读量数据的统计分析和展示之外,还有一个文章“昨日热榜”的排序也是可视化的一部分。经过这次的改造,网站已经可以自行统计一些“有效的流量”,而不需要再依靠第三方流量统计平台。这篇文章就分享一下我是如果做的。
我的想法
首先做这个事情之前其实我已经有了比较清晰的想法,包括需要统计什么数据,如果统计数据,如何展示数据等。
统计什么数据
说到流量,一般的统计软件无非就是统计网站的PV(Page View : 页面访问量。 用户每次刷新页面被计算一次)和UV(Unique Visitor: 独立访客,独立访客是指某站点被多少台电脑访问过,有的网站是以用户电脑的Cookie作为统计依据),而我的网站作为一个博客类型的网站,当然主要的目的还是分享博客文章,所以我只关注于文章的访问量,并且在之前设计文章模型的时候对于文章的阅读量就进行了统计,每篇文章的阅读量就是我需要统计的基础数据。
我文章的阅读量计算规则是每个用户在30分钟内重复访问只计算一次,并且直接忽略文章的作者和网站管理员的访问。所以这个阅读量其实是结合了PV和UV的一个混合计算。
目标数据已经确定了,统计的具体是数据就好说了,就是每天每篇文章的当前阅读量,并且还记录了每个小时的总阅读量。
如何统计数据
我这里使用的方案是利用定时任务来定时统计,也就是我博客之前增加过的定时任务功能,定时任务设定的频率是每个小时的59分执行,这样可以保证统计到每个小时的最终数据以及每天的最终数据。并且将需要持久化的统计的数据写入模型,将需要在可视化中使用的数据写入redis。这样既可以保留历史数据又可以减少统计计算的消耗。
如何展示数据
我第一想到的是使用 echarts.js 来做可视化报表,这个库最开始是百度的一个开源项目,后来交给 Apache 维护,我之前做可视化的时候用过,感觉挺好用的。
数据统计的具体方案
创建“文章浏览量统计”模型
首先,为了历史数据持久化,我创建了一个名为“文章浏览量统计”的模型,这个模型其实挺简单的,因为里面存放的数据格式是json格式,这样可以比较灵活的扩展。
看一下这个模型:
class ArticleView(models.Model):
date = models.CharField('统计日期', max_length=10, unique=True) # 唯一性
body = models.TextField(verbose_name='统计数据')
create_date = models.DateTimeField(verbose_name='录入时间', auto_now_add=True)
update_date = models.DateTimeField(verbose_name='更新时间', auto_now=True)
class Meta:
verbose_name = '文章浏览量统计'
verbose_name_plural = verbose_name
ordering = ['create_date']
def __str__(self):
return self.date
这个模型其实只有两个有效字段,一个是date字段,用来当做唯一键,也就是每天的日期,第二个字段是body,也就是统计数据,长字符串,实际的内容是json格式。
这里body里面存的格式内容如下:
{
"total_views": 662882,
"today_views": {
"90": 0,
"89": 106,
"3": 29283,
"2": 20850,
"1": 25544
},
"every_hours": {
"10": 662802,
"15": 662882
}
}
创建基础数据定时任务
我的定时任务模块被我统一了格式,就是 actions.py 文件里面写具体的任务逻辑,而 tasks.py 文件里面则是定义定时任务的调用。
先来看这个最基本的统计函数的定义,这个函数是写入基础数据:
def action_write_or_update_view():
"""
写入或更新当天的文章阅读量
@return:
"""
from django.db.models import Sum
from blog.models import Article
from blog.models import ArticleView
date_value = datetime.today().strftime('%Y%m%d')
this_hour = datetime.now().strftime('%H')
total_views = Article.objects.aggregate(Sum('views'))['views__sum'] or 0
article_views_dict = {}
# 获取所有文章的id和views字段
articles = Article.objects.all()
# 将id和views存储在字典中
for article in articles:
article_views_dict[article.id] = article.views
body_data = {
'total_views': total_views, # 当前阅读总计
'today_views': article_views_dict, # 当前阅读详情
'every_hours': {} # 当前每小时阅读统计
}
obj = ArticleView.objects.filter(date=date_value)
if obj and json.loads(obj.first().body).get('every_hours'):
every_hours = json.loads(obj.first().body).get('every_hours')
else:
every_hours = {}
every_hours[this_hour] = total_views
body_data['every_hours'] = every_hours
body = json.dumps(body_data)
# 写入或更新一条实例
ArticleView.objects.update_or_create(date=date_value, defaults={'body': body})
这个函数调用的时候会自动统计当天(准确说是当时,只不过按照当天日期更新)的每篇文章的阅读量,以及总阅读量,还有当前这个小时的总阅读量。
这三个基础数据的作用:
total_views:当天总阅读量,可以结合每天的数据,统计每日阅读量趋势today_views:当天每篇文章的总阅读量的详情,可以对某天的文章进行阅读量排行,比如“昨日热榜”就是对昨天的文章阅读量排序every_hours:当前每个小时的总阅读量,可以统计每天每个小时的阅读量变换趋势
有了这些基础数据,就可以进行横向和纵向的数据对比,也就能做出一些可视化效果。
创建可视化数据定时任务
基础数据的定时任务是为了将基础数据持久化到数据库中长期使用,而可视化的数据肯定不是能直接使用基础数据的,是需要进行转换和计算的,为了减小这个计算的频率和资源浪费,这个计算就交过定时任务来做,并且把结果存到redis。
我这里定义了一个类来统计数据:
class ArticleViewsTool:
key = RedisKeys.views_statistics
@staticmethod
def get_last_week_dates():
"""
获取上周日期列表
@return:
"""
today = datetime.today()
last_monday = today - timedelta(days=(today.weekday() + 7))
last_week_dates = [last_monday + timedelta(days=i) for i in range(7)]
# 将日期格式化为字符串,并返回列表
last_week_dates_str = [date.strftime('%Y%m%d') for date in last_week_dates]
return last_week_dates_str
@staticmethod
def get_this_week_dates():
"""
获取本周日期列表
@return:
"""
today = datetime.today()
this_monday = today - timedelta(days=today.weekday())
this_week_dates = [this_monday + timedelta(days=i) for i in range(today.weekday() + 1)]
# 将日期格式化为字符串,并返回列表
this_week_dates_str = [date.strftime('%Y%m%d') for date in this_week_dates]
return this_week_dates_str
@staticmethod
def get_day_of_week(date_string):
# 将输入的日期字符串转换为日期对象
date_object = datetime.strptime(date_string, '%Y%m%d')
# 获取星期几的数字(0代表星期一,1代表星期二,以此类推)
day_of_week = date_object.weekday()
# 映射数字到星期几的字符串
days_of_week = ['周一', '周二', '周三', '周四', '周五', '周六', '周日']
day_str = days_of_week[day_of_week]
return day_str
@staticmethod
def get_yesterday(date_string):
# 将输入的日期字符串转换为日期对象
date_object = datetime.strptime(date_string, '%Y%m%d')
yesterday = date_object - timedelta(days=1)
return yesterday.strftime('%Y%m%d')
@staticmethod
def get_date_total_views(date):
"""
获取一个日期的阅读量总数,没有就返回0
@param date: 20231208
@return:
"""
from blog.models import ArticleView
obj = ArticleView.objects.filter(date=date)
if obj:
total_views = json.loads(obj.first().body)['total_views']
return total_views
return 0
@staticmethod
def get_hours_views(date):
"""
获取一个日期的每小时的数据,没有则返回{}
@param date:
@return:
"""
from blog.models import ArticleView
obj = ArticleView.objects.filter(date=date)
if obj and json.loads(obj.first().body).get('every_hours'):
every_hours = json.loads(obj.first().body)['every_hours']
return every_hours
return {}
def set_data_to_redis(self):
"""
从ArticleView模型中获取数据,并分析入库到redis
@return:
"""
from django.core.cache import cache
today_str = datetime.today().strftime('%Y%m%d')
total_views = self.get_date_total_views(today_str)
data = {
'last_week_views': {}, # 上周数据
'this_week_views': {}, # 本周数据
'total_views': total_views, # 当天当时数据
}
for last_day in self.get_last_week_dates():
yesterday = self.get_yesterday(last_day)
last_day_views = self.get_date_total_views(last_day)
yesterday_views = self.get_date_total_views(yesterday)
if last_day_views and yesterday_views:
last_day_key = self.get_day_of_week(last_day)
data['last_week_views'][last_day_key] = last_day_views - yesterday_views
for this_day in self.get_this_week_dates():
yesterday = self.get_yesterday(this_day)
this_day_views = self.get_date_total_views(this_day)
yesterday_views = self.get_date_total_views(yesterday)
if this_day_views and yesterday_views:
this_day_key = self.get_day_of_week(this_day)
data['this_week_views'][this_day_key] = this_day_views - yesterday_views
cache.set(self.key, data, 3600 * 24 * 7)
return data
调用 set_data_to_redis 函数就可以将两周的每天阅读量数据写入redis中,格式如下:
{'last_week_views': {'周三': 150, '周四': 300, '周五': 2280, '周六': 230, '周日': 210}, 'this_week_views': {'周一': 80, '周二': 200}, 'total_views': 601736}
这个数据是我的可视化报表需要的数据格式。
定义标签函数
当然,其实写入可视化数据到redis的操作不一定需要放到定时任务里面,也可以放到标签函数里面,当页面被请求的时候计算一次,后面就使用redis里面的数据就行。
比如我这里计算今天和昨天的每个小时的阅读量的标签函数:
def get_hours_data_by_date(date):
"""
获取一个日期的小时数据
@param date:
@return: dict
"""
obj = ArticleView.objects.filter(date=date)
if obj and json.loads(obj.first().body).get('every_hours'):
return json.loads(obj.first().body).get('every_hours')
return {}
@register.simple_tag
def get_hours_views_from_redis():
"""
从redis获取当天和昨天每小时的阅读量,获取不到则返回空格式
@return:
"""
this_hour = datetime.now().strftime('%Y%m%d%H')
redis_key = RedisKeys.hours_views_statistics.format(hour=this_hour)
redis_value = cache.get(redis_key)
if redis_value:
return redis_value
else:
data = [['product', '今天每小时阅读量', '昨天每小时阅读量']]
pre_date_str = (datetime.today() - timedelta(days=2)).strftime('%Y%m%d') # 前天
yes_date_str = (datetime.today() - timedelta(days=1)).strftime('%Y%m%d') # 昨天
thi_date_str = datetime.today().strftime('%Y%m%d') # 今天
pre_hours_data = get_hours_data_by_date(pre_date_str)
yes_hours_data = get_hours_data_by_date(yes_date_str)
thi_hours_data = get_hours_data_by_date(thi_date_str)
hour_list = [str(h).zfill(2) for h in range(0, 24)]
for hour in hour_list:
if hour == '00':
if thi_hours_data.get(hour) and yes_hours_data.get('23'):
thi_value = thi_hours_data[hour] - yes_hours_data['23'] # 今天00点访问量
else:
thi_value = '-'
if yes_hours_data.get(hour) and pre_hours_data.get('23'):
yes_value = yes_hours_data[hour] - pre_hours_data['23'] # 昨天00点访问量
else:
yes_value = '-'
else:
last_hour = str(int(hour) - 1).zfill(2)
if thi_hours_data.get(hour) and thi_hours_data.get(last_hour):
thi_value = thi_hours_data[hour] - thi_hours_data[last_hour]
else:
thi_value = '-'
if yes_hours_data.get(hour) and yes_hours_data.get(last_hour):
yes_value = yes_hours_data[hour] - yes_hours_data[last_hour]
else:
yes_value = '-'
data.append([hour, thi_value, yes_value])
cache.set(redis_key, data, 3600) # 缓存1小时即可,每小时必须更新
return data
其实只要缓存的过期时间设置的好,比如我这里有的数据按照日期缓存,有的按照小时缓存,都可以保证在有效时间里面缓存的数据是有效的。
可视化
可视化数据得到了,剩下的就是可视化展示了。
创建看板页面
我单独定义了一个页面来展示可视化看板,页面模板为 dashboard.html,然后在视图里面我设置了访问权限,只能管理员可以访问。
引用 echarts.js
在页面中使用 echarts.js 非常简单,只需要使用 cdn 来添加就行:
<script src="https://cdn.bootcss.com/echarts/5.4.3/echarts.min.js"></script>
然后就可以愉快的使用 echarts.js 来添加图标了,具体的添加方式参数考官方文档就行,非常的简单,
建议在使用数据的时候使用数据集的方式,参考文档为 在数据集中设置数据
看一下我这里的使用方式:
<div class="row justify-content-center">
<div class="mb-3" id="day_views_box" style="width: 100%;height:340px;"></div>
{% get_views_data_from_redis as day_views_data %}
<div id="day_views_data" style="display: none;">{{ day_views_data|json_script:"day_views_data" }}</div>
<script type="text/javascript">
// 基于准备好的dom,初始化echarts实例
const myDayViewsData = JSON.parse(document.getElementById("day_views_data").textContent);
const myDayViewsChart = echarts.init(document.getElementById('day_views_box'));
// 指定图表的配置项和数据
option = {
toolbox: {
show: true,
feature: {
magicType: {type: ['line', 'bar']},
saveAsImage: {}
}
},
title: {
text: '文章两周阅读量趋势图',
x: 'center',
y: 'bottom',
textStyle: {fontSize: 18}
},
legend: {data: ['本周阅读量', '上周阅读量']},
dataset: {
source: myDayViewsData
},
xAxis: {type: 'category'},
yAxis: {type: 'value'},
series: [
{
type: 'line',
label: {
show: true,
position: 'top',
textStyle: {
fontSize: 12
}
}
},
{
type: 'line',
label: {
show: true,
position: 'top',
textStyle: {
fontSize: 12
}
}
}
]
};
// 使用刚指定的配置项和数据显示图表。
myDayViewsChart.setOption(option);
</script>
</div>
这里的思路就是使用标签函数 get_views_data_from_redis 拿到数据,然后转换成js能读懂的数据存到一个隐藏标签里面,然后按照echarts.js的图标的格式去填写展示字段的属性就行了。
可视化效果
本文更新于 2024-06-25,可视化效果经过了一些改进,下面是改进后的效果:
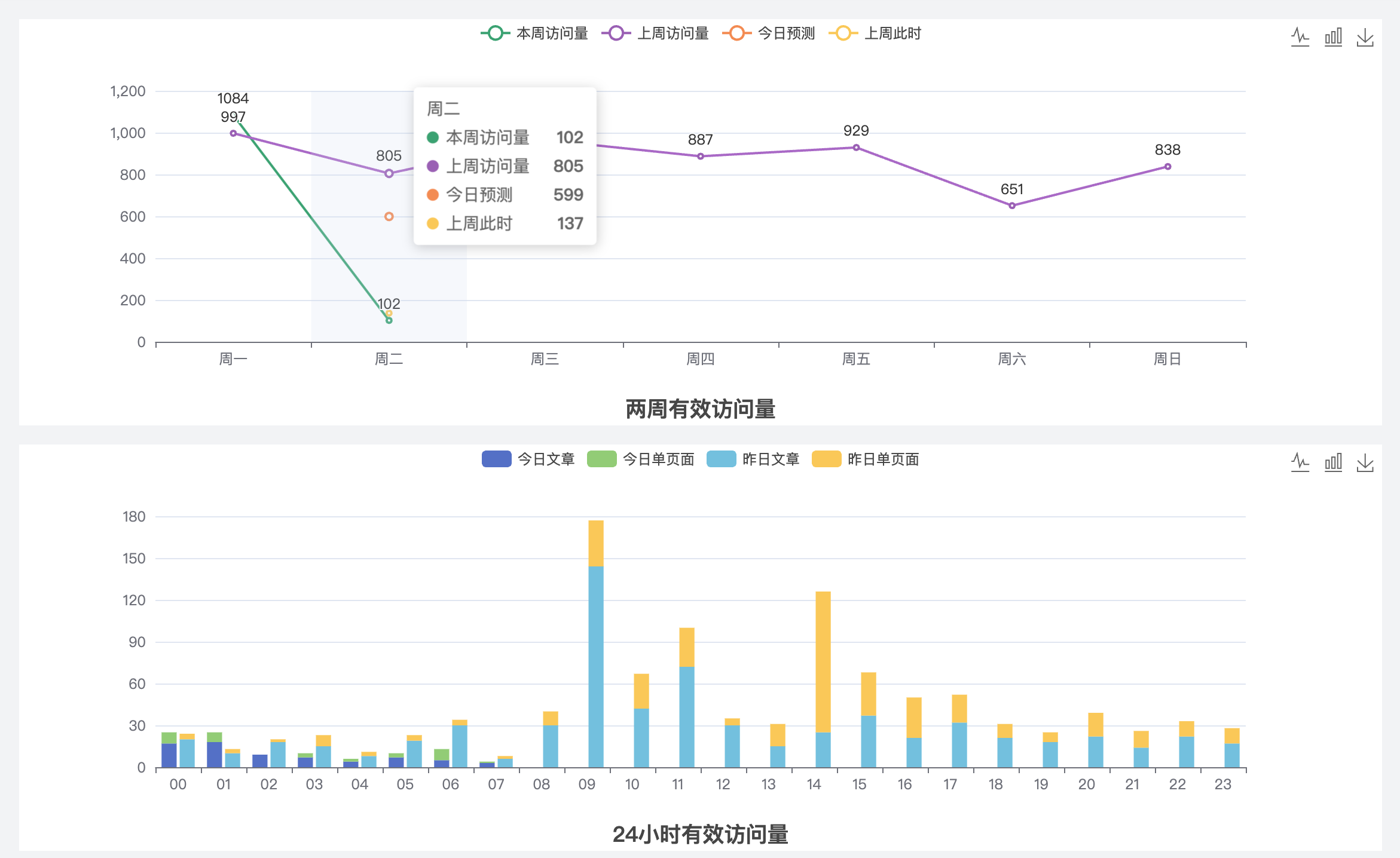
上面第一个图可以纵向看到一周的阅读量趋势,并且可以横向对比上周的情况,第二个图可以看到一天24小时中每个时段的访问情况,并且访问量按照文章访问和单页面访问分别显示。
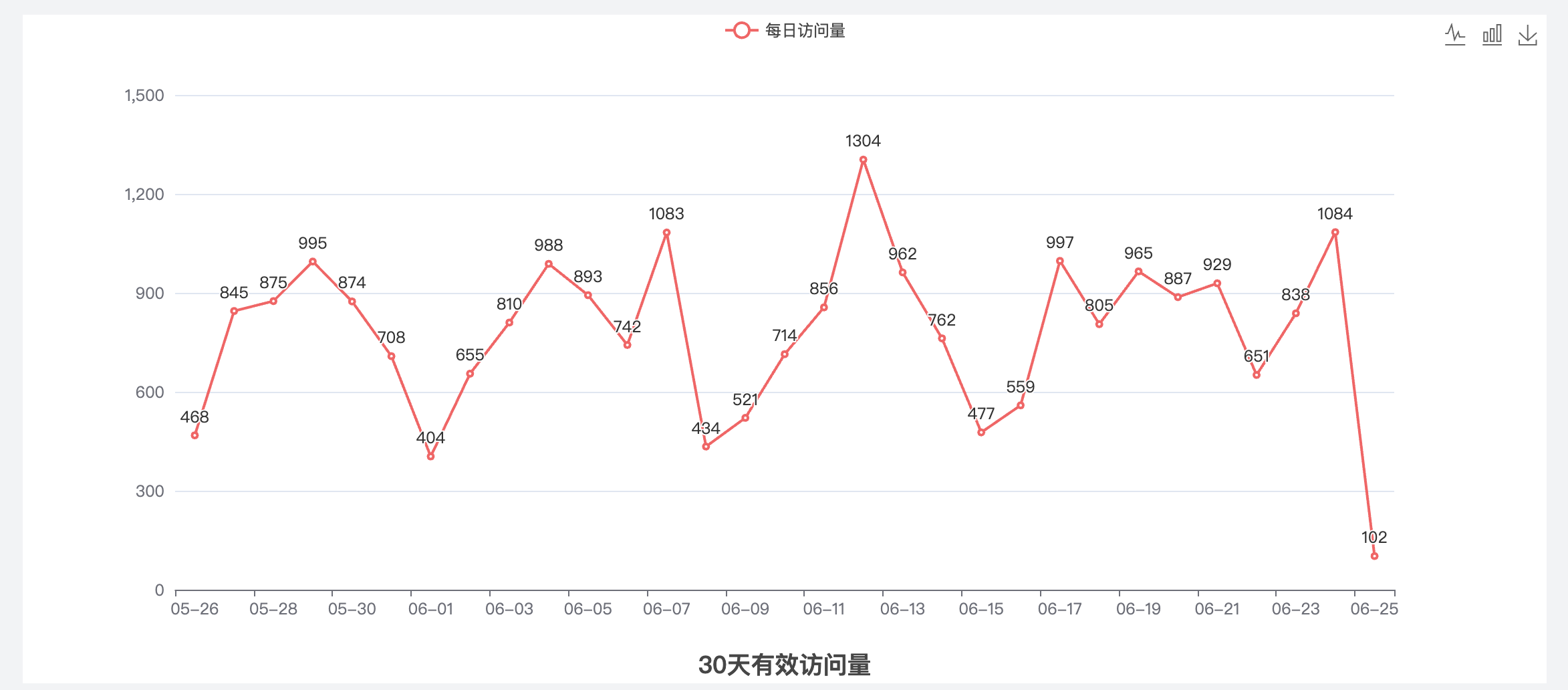
上面这个图看到的是最近30天的每日访问量情况。
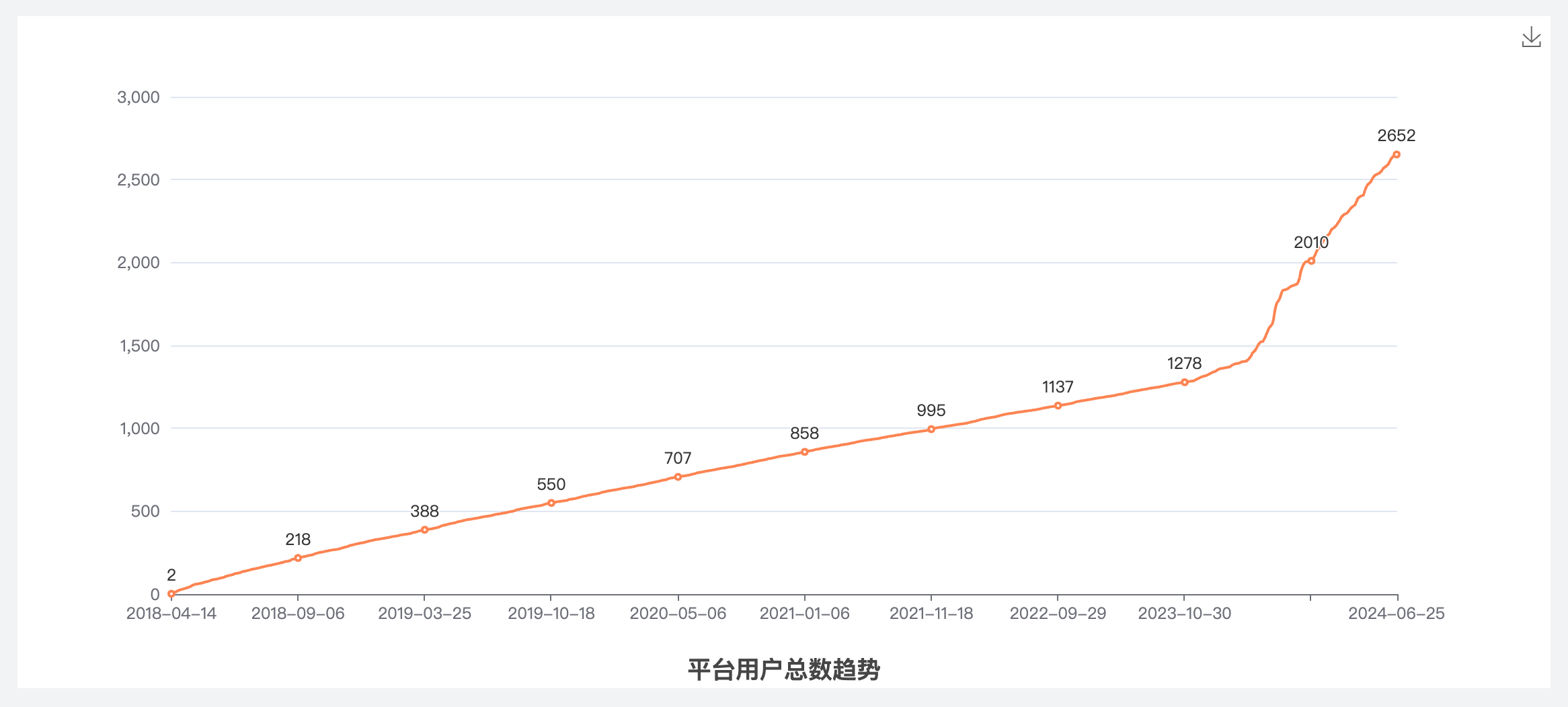
这个图是显示用户数增长趋势。
技巧
默认显示最大值
在统计用户数量增长曲线的时候,由于数据量很多,所以显示的数据是 echart 自动计算的,这导致不显示最后一个数据的值,在看了很多次文档之后终于找到了相关参数:xAxis.axisLabel. showMaxLabel
参数的解释:是否显示最大 tick 的 label。可取值 true, false, null。默认自动判定(即如果标签重叠,不会显示最大 tick 的 label)。
版权声明:如无特殊说明,文章均为本站原创,转载请注明出处
本文链接:https://tendcode.com/subject/article/ECharts-for-web/
许可协议:署名-非商业性使用 4.0 国际许可协议