上周末给网站添加了文章访问量的统计分析,并做成了可视化图标。但是之前统计的都是文章的阅读量,这个阅读量是文章模型特有的属性,于是为了能够统计到其他页面的浏览量,我对流量统计方式进行了改良,可以做到所有页面通用。
我的想法
如何记录流量
关于如何记录流量这个事情,我第一想法当然是参考文章模型的做法,需要给页面添加一个模型字段将每次的访问追加到数据库中。但是文章是用模型来记录的,而其他页面根本没有模型只有视图,就算有模型总不能每个模型去单独添加字段吧。
所以我决定单独创建一个模型去记录流量,只需要给每个页面设置一个唯一键用来绑定页面就行。
如何统计流量
统计流量的方式就没有什么特别的,同样是参考文章的统计方式,就是在视图里面添加流量增加的逻辑,并且同样参考文章的统计方式,可以设置流量的统计缓存。
当然,每个页面都有自己的视图,总不可能大费周章的去给每个视图添加流量统计逻辑吧,所以肯定需要一个通用的函数来做这个事情,为了方便使用,可以将函数设计成装饰器。
如何过滤流量
给每个视图添加流量统计其实挺简单,但是很多视图有多种请求方式,而流量统计主要是为了统计用户的真实访问,所以其实还需要做一些过滤。
关于过滤这个问题,其实大可不必太较真,因为太较真的话,这个话题展开那就复杂了,我更希望能简单的过滤掉无关的流量,所以我就过滤掉非GET请求就行。
具体方案
创建流量统计模型
下面这个是我创建的流量统计模型:
# 单页面浏览量记录模型,记录一些单页面的浏览量
class PageView(models.Model):
url = models.CharField('页面地址', max_length=255, unique=True) # 唯一性
name = models.CharField('页面名称', max_length=255, blank=True, null=True)
views = models.IntegerField('浏览量', default=0)
is_compute = models.BooleanField('是否计算到访问量', default=True) # 有的页面只记录,不计算
create_date = models.DateTimeField(verbose_name='录入时间', auto_now_add=True)
update_date = models.DateTimeField(verbose_name='更新时间', auto_now=True)
def __str__(self):
return self.url
class Meta:
verbose_name = "单页面浏览量"
verbose_name_plural = verbose_name
ordering = ['url']
def update_views(self):
self.views += 1
self.save(update_fields=['views', 'update_date'])
这个模型只有两个意义比较大的字段,就是url和views,url就是唯一键,用来绑定一个唯一的页面,这个值需要每个页面指定好然后传过来,name字段就是一个描述的用处,没有实际作用。
url这个字段具体传什么我想好了,就是每个页面url的别名,这样不仅仅能保证唯一,还有一个好处就是通过这个别名可以直接获取到页面的真实地址。
模型存储数据之后的格式如下:

创建流量统计装饰器
我创建的的流量统计装饰器如下:
def add_views(url, name=None, is_cache=True):
"""
单页面访问量统计的视图函数装饰器
@param is_cache: 是否使用缓存判断访问,跟文章的逻辑一样
@param name: 页面名称,也可以是描述,方便辨认,没有实际作用
@param url: 全局唯一,tool:ip这种格式,可以被解析成URL
@return:
"""
def decorator(func):
def wrapper(request, *args, **kwargs):
result = func(request, *args, **kwargs)
# ******* 浏览量增加的逻辑 *******
# 仅访问页面的时候才进行计算,接口调用不计算,管理员访问也不计算
if request.method == "GET" and not request.is_ajax() and not request.user.is_superuser:
# 获取或者创建一个实例
page_views = PageView.objects.filter(url=url)
if page_views:
obj = page_views.first()
else:
obj = PageView(url=url, name=name, views=0)
obj.save()
if is_cache: # 要判断缓存,则存状态
cache_key = f'page_views:read:{url}'
is_read_time = request.session.get(cache_key)
if not is_read_time:
obj.update_views()
request.session[cache_key] = time.time()
else:
t = time.time() - is_read_time
if t > 60 * 30:
obj.update_views()
request.session[cache_key] = time.time()
else:
obj.update_views()
# ******* 浏览量增加的逻辑 *******
return result
return wrapper
return decorator
这个装饰器有3个参数,其中url是必填参数,这个也就是模型里面的唯一键,name字段也是模型里面的字段。is_cache字段是用来判断是否需要将页面访问的历史记录到用户的session里面,这个逻辑跟文章一样,只不过文章是一定会记录,而这个装饰器是可以选择记录。
这个装饰器里面进行了流量过滤,只有GET请求的流量才会经过处理,并且忽略管理员的访问,这些过滤条件跟文章类似。
给视图添加装饰器
装饰器的使用很简单,比如下面是给一个普通的视图函数添加流量统计:
@add_views('tool:tax', '综合所得年度汇算')
def tax(request):
return render(request, 'tool/tax.html')
就是这么简单,只需要将装饰器添加到视图函数上面并给视图传入一个唯一的别名就行,这里统一使用视图在url.py文件中的别名来当做唯一键,然后可以传入页面的名称,方便后台查看。
给视图类添加装饰器
给视图添加装饰器很简单,就直接给视图函数添加就行,但是很多视图是使用的类视图,根本没有视图函数,这种如何添加?
其实这个问题我最开始也不太清楚,经过了一番查找和学习,我才知道了Django里面其实有一个非常重要的装饰器,可以给视图类添加使用,那就是method_decorator装饰器。
这个装饰器的用法有兴趣可以去查一下(这里有个文章可以看看:装饰类视图:Django内置method_decorator),学习到这个装饰器之后真的有点惊到我,感觉很实用。
使用方式如下:
@method_decorator(add_views('blog:timeline', '时间线'), name='get')
class TimelineView(generic.ListView):
model = Timeline
template_name = 'blog/timeline.html'
context_object_name = 'timeline_list'
def get_ordering(self):
return '-update_date',
method_decorator装饰器使用到类上面的时候需要穿name参数,这个参数就是这个类的一个函数,也就是告诉method_decorator里面的装饰器是装饰谁的。因为我们的流量统计都是针对GET请求的,所以自然我这里name参数就是给的get。
统计数据
统计数据就不用多数量,随着网页的访问,流量已经都记录到了数据库,数据的统计和分析方式跟文章的就没任何区别。
我这里在之前的统计分析的基础上把文章的浏览量和单页面的浏览量进行了分别统计,然后再汇总,这样可以看到流量的分布。
修改之后,写入数据库的统计数据格式变成了如下格式:
{
"total_views_num": 665349,
"article_views_num": 664133,
"page_views_num": 1216,
"article_views": {
"90": 27,
"87": 207
},
"page_views": {
"blog:about": 10,
"tool:word_cloud": 209
},
"article_every_hours": {
"11": 664133
},
"page_every_hours": {
"11": 1216
}
}
- total_views_num:当前总流量
- article_views_num :当前文章的总流量
- page_views_num :当前单页面的总流量
- article_views :当前每篇文章的流量
- page_views :当前每个单页面的流量
- article_every_hours :每个小时文章的流量
- page_every_hours :每个小时单页面的流量
可视化效果
当我将文章和单页面的流量分别记录和分析之后,就可以看到每天每个小时里面文章和单页面的流量分布情况了,效果如下:
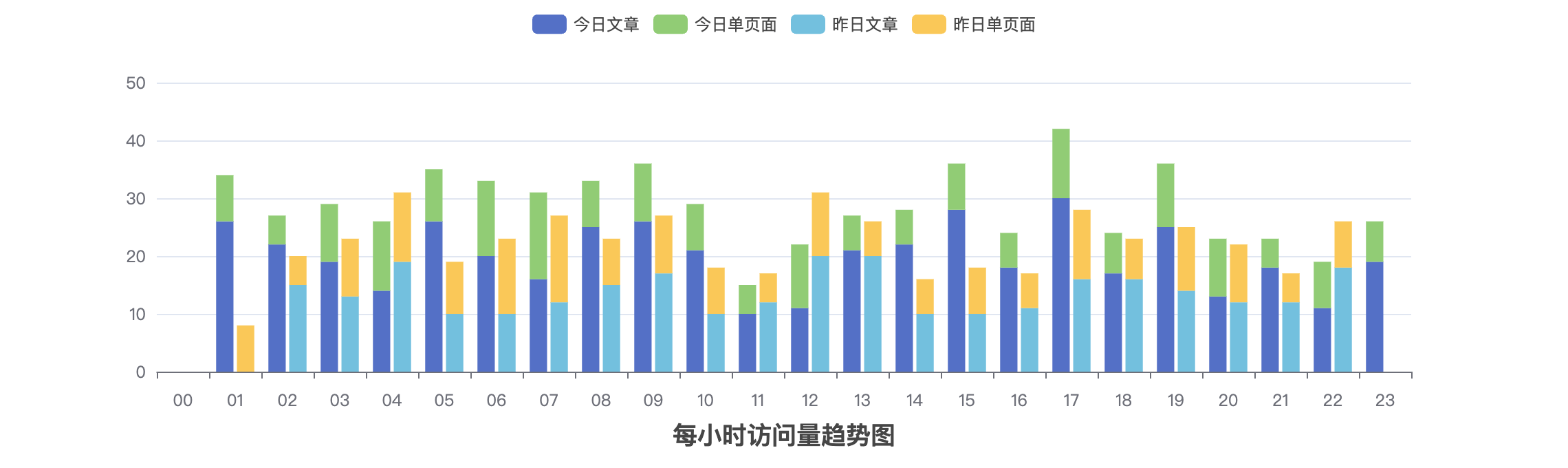
当然,有了基础数据之后,这里自然也可以对单页面进行流量排序。
后记
请求头过滤
因为搜索引擎经常会有爬虫光顾平台,为了过滤掉这部分爬虫,可以增加一个请求头的校验,直接忽略掉搜索引擎的访问。
这是一个简单的过滤函数:
def check_request_headers(headers_obj):
"""
校验请求头信息,比如识别User-Agent,从而过滤掉该请求
@param headers_obj: request.headers对象
@return:
use: flag = check_request_headers(request.headers)
"""
# 常见的搜索引擎爬虫的请求头,还有Python的
# 无请求头或者请求头里面包含爬虫信息则返回False,否则返回True
user_agent_black_keys = ['spider', 'bot', 'python']
if not headers_obj.get('user-agent'):
return False
else:
user_agent = str(headers_obj.get('user-agent')).lower()
for key in user_agent_black_keys:
if key in user_agent:
logger.warning(f'Bot/Spider request user-agent:{user_agent}')
return False
return True
一般的搜索引擎的爬虫的请求头的字段都有明确的可识别性,虽然人工发起的爬虫可以伪造请求头越过这个过滤,但是这个过滤可以对大部分搜索引擎有效就行,所谓“防君子不防小人”。
版权声明:如无特殊说明,文章均为本站原创,转载请注明出处
本文链接:https://tendcode.com/subject/article/django-views/
许可协议:署名-非商业性使用 4.0 国际许可协议