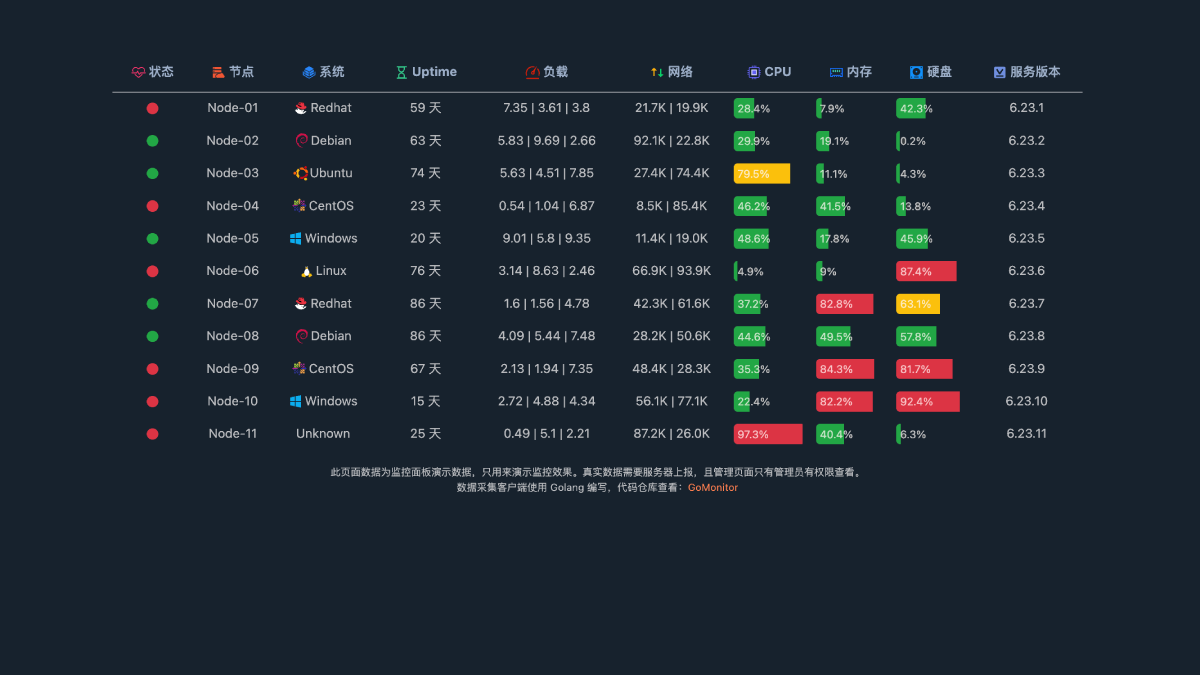

 Hopetree
11月前
Hopetree
11月前
Python 日志中 exc_info 和 stacklevel 参数的使用场景
作为一个主开发语言是 Python 的运维程序员,最近才学到了两个关于日志设置的小技巧,解决了我以前经常会遇到但是忽略了的问题:一个是关于错误日志经常没有记录错误的 Traceback 信息导致定位困难,另一个是日志被封装后无法显示真实的调用行号的问题。
作为一个主开发语言是 Python 的运维程序员,最近才学到了两个关于日志设置的小技巧,解决了我以前经常会遇到但是忽略了的问题:...
 Hopetree
11月,1 周前
Hopetree
11月,1 周前
被国产某SSL续签工具背刺
这篇文章说一下被某SSL续签工具背刺的事情,同时再一次分享 NPM 在SSL证书配置的高级用法。大概一到两年前,由于当时的SSL证书政策改革,我被安利 httpsok 这个证书续签工具,当时加了开发者微信并进入沟通群,很快就使用上了这个工具,我记得当时推广就是...
这篇文章说一下被某SSL续签工具背刺的事情,同时再一次分享 NPM 在SSL证书配置的高级用法。大概一到两年前,由于当时的SSL...
 Hopetree
11月,2 周前
Hopetree
11月,2 周前
Redis “Cannot assign requested address” 故障排查实录
昨天为了验证我们家用服务器的断电自动重启能力,我重启了服务器,然后导致了一个系统服务一致连不上 redis,经过一个多小时的排查,最终解决了问题。由于这次故障的现象非常的特别,特别到我根本无法理解,所以我觉得有必要把大概的排查过程和结论记录下来。
昨天为了验证我们家用服务器的断电自动重启能力,我重启了服务器,然后导致了一个系统服务一致连不上 redis,经过一个多小时的排查...
 Hopetree
11月,2 周前
Hopetree
11月,2 周前
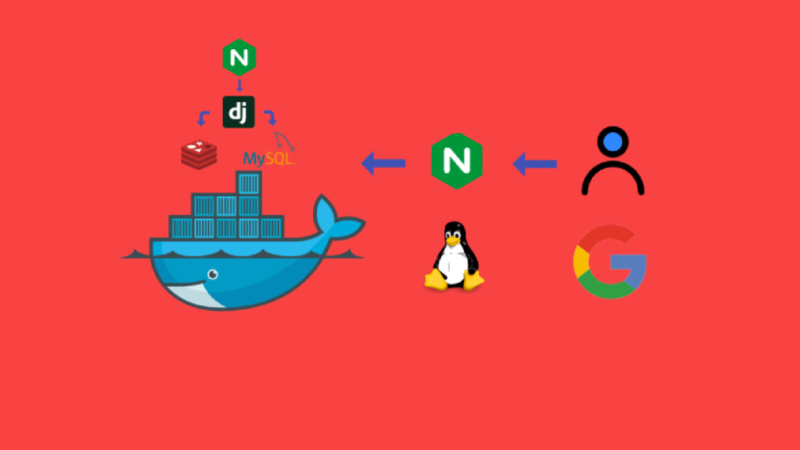
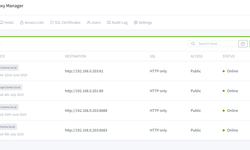
Nginx Proxy Manager:Docker环境下反向代理的绝佳选择
在使用Docker构建多服务架构时,管理众多服务端口常常让人头疼。每个容器都有自己的端口,而直接暴露这些端口不仅可能导致端口冲突,还会增加配置复杂性和安全风险。幸运的是,Nginx Proxy Manager(NPM)为我们提供了一个优雅的解决方案。今天,我将...
在使用Docker构建多服务架构时,管理众多服务端口常常让人头疼。每个容器都有自己的端口,而直接暴露这些端口不仅可能导致端口冲突...
 Hopetree
11月,2 周前
Hopetree
11月,2 周前
来自网信办的安全巡检报告:SSL弱密码整改
今天收到了社区的工作人员的电话,并且给我发个一个网信办的通报文件以及一个关于我的个人网站存在 SSL 弱密码漏洞风险的安全检查报告,大意就是网信办通过安全漏洞扫描扫出我的个人网站存在 SSL 弱密码漏洞风险,需要处理。
今天收到了社区的工作人员的电话,并且给我发个一个网信办的通报文件以及一个关于我的个人网站存在 SSL 弱密码漏洞风险的安全检查报...
Hopetree
11月,2 周前
Django 中 locale 的用法:自定义翻译
最近在使用 Django 开发一个股票数据采集平台,在开发过程中想要把后台管理页面显示的英文改成中文显示,然后就得知了 locale 的存在和用法。Django 作为功能强大的 Python Web 框架,内置了完善的国际化(i18n)和本地化(l10n)机制...
最近在使用 Django 开发一个股票数据采集平台,在开发过程中想要把后台管理页面显示的英文改成中文显示,然后就得知了 loca...
Hopetree
1 年,1月前
Linux 系统 OOM 排查指南
OOM是指系统可用内存耗尽时,内核触发OOM Killer机制自动杀掉部分进程以释放内存资源。这种情况通常发生在系统负载过高、内存泄漏或大量进程同时占用大量内存时。发生OOM可能导致关键进程被杀,系统性能下降甚至服务中断。文章从查看系统日志、使用journal...
OOM是指系统可用内存耗尽时,内核触发OOM Killer机制自动杀掉部分进程以释放内存资源。这种情况通常发生在系统负载过高、内...
 Hopetree
1 年,2月前
Hopetree
1 年,2月前
使用 Docker 搭建个人私有化 Git 服务:Gitea + SSH 配置实践
本文介绍了如何使用 Docker 搭建轻量级的私有 Git 服务 Gitea,适合个人或小团队使用。内容涵盖 Gitea 的资源优势、容器化部署步骤、端口映射与数据挂载方法,并重点讲解了 SSH 配置中的常见问题及解决方案,确保 clone 和 push 操作...
本文介绍了如何使用 Docker 搭建轻量级的私有 Git 服务 Gitea,适合个人或小团队使用。内容涵盖 Gitea 的资源...
 Hopetree
1 年,2月前
Hopetree
1 年,2月前
Git 提交信息规范与最佳实践
在日常开发中,Git 提交信息(commit message)不仅仅是记录代码变更的日志,更是团队协作、项目管理和自动化流程的核心组成部分。良好的提交信息规范可以帮助团队提高协作效率、自动化生成变更日志(changelog)、更清晰地回溯历史。
在日常开发中,Git 提交信息(commit message)不仅仅是记录代码变更的日志,更是团队协作、项目管理和自动化流程的核...
 Hopetree
1 年,2月前
Hopetree
1 年,2月前
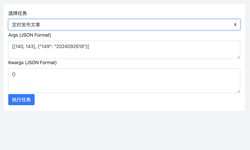
让定时任务支持执行自定义脚本
我在项目中实现了定时任务功能,使用的 Celery,目前的任务都是执行的写到项目代码中的函数,也就是说每当我要创建一个新的执行内容都必须更新项目代码。因此,我想要实现一个新功能,就是可以将要执行的任务以脚本的形式添加到数据库中,然后定时任务可以选择这些脚本去执...
我在项目中实现了定时任务功能,使用的 Celery,目前的任务都是执行的写到项目代码中的函数,也就是说每当我要创建一个新的执行内...


